Bento vs. SageMaker: Which Inference Platform Is Right for Enterprise AI?
Authors

Last Updated
Share

For Heads of AI, choosing the right inference platform isn’t just a technical decision, but a strategic one. The wrong choice can slow time-to-market, inflate GPU costs, and tie scarce engineering resources to infrastructure instead of innovation. The right choice accelerates the delivery of AI products, gives predictable infrastructure costs, and lets your team scale without adding headcount.
AWS SageMaker is a comprehensive ML lifecycle platform with inference included as one of many capabilities. For enterprises, this often means inference is generic, not deeply optimized, and the outcomes show up as higher costs, slower deployments, and limited flexibility.
The Bento Inference Platform is purpose-built for production inference. It combines fast deployments, advanced performance optimizations, and multi-cloud flexibility, helping enterprises meet latency SLAs, control costs, and future-proof their AI infrastructure.
This analysis compares both solutions across scalability, workflows, cost, and enterprise requirements.
SageMaker In Enterprise AI#
AWS SageMaker is positioned as the hub for the entire AWS ML ecosystem, covering data preparation to deployment. It’s a familiar choice for AWS-native teams, offering convenience and tight integration.
However, SageMaker often falls short when enterprises need specialized, cost-efficient inference at scale.
Where SageMaker fits best#
SageMaker works well for organizations that are deeply invested in AWS infrastructure and value the convenience of an all-in-one environment.
- Unified governance and security: Integrates directly with IAM, VPC, KMS, and CloudWatch, giving enterprises a single pane of glass for governance, observability, and compliance.
- Framework-ready environment: Preconfigured support for PyTorch, TensorFlow, and XGBoost makes initial deployments straightforward.
- Container support: Allows bring-your-own-container deployments for teams standardizing on Docker within AWS.
For AWS-centric teams, these features make SageMaker a fast way to prototype and manage early ML projects inside the AWS ecosystem.
Where SageMaker shows its limits#
For large-scale inference, SageMaker’s general-purpose design introduces friction and cost inefficiency.
- Hidden scaling costs: Multi-model endpoints share GPU and CPU resources, leading to latency spikes and memory churn that erode cost savings.
- Operational rigidity: Scaling policies, YAML-based configs, and AWS-specific tooling slow iteration and increase DevOps overhead.
- Vendor lock-in: Workloads are tied to AWS runtimes, making cross-cloud or on-prem deployment complex and time-consuming.
- Inference trade-offs: Broad coverage comes at the expense of depth; SageMaker’s inference layer lacks fine-grained control and optimization flexibility.
In short, SageMaker provides convenience for teams anchored in AWS, but its generic inference layer struggles to deliver the performance, portability, and cost control that growing enterprise AI workloads demand.
What Sets The Bento Inference Platform Apart#
While SageMaker covers the full ML lifecycle, Bento focuses on the most business-critical mile: inference. It’s purpose-built for speed, flexibility, and efficiency where it matters most.
Deploy anywhere, scale everywhere#
- Run inference workloads across private cloud, multi-cloud, on-prem, or hybrid environments.
- Avoid AWS GPU pricing and capacity limits by sourcing compute from the best provider for cost or availability.
- Deploy regionally to meet compliance and latency requirements without rearchitecting.
Future-proof with open standards#
- Built on BentoML, an open-source framework that packages models, dependencies, and configurations in standard OCI containers.
- Workloads stay portable, even if a team stops using BentoCloud.
- Eliminate lock-in and reduce infrastructure risk with an “escape hatch” guarantee.
Faster time-to-deploy for engineering and data teams#
- Define and deploy inference services directly in Python, no YAML or complex container builds.
- Customize preprocessing, postprocessing, and business logic directly within the model deployment pipeline.
- Empower data scientists to push production-grade models independently, accelerating iteration cycles.
Optimized for performance and reliability#
- Adaptive batching adjusts batch size and latency windows in real time to balance throughput and responsiveness.
- Chain multiple models and distributed services with optimized resource utilization and scalability.
- Fast cold starts and intelligent caching maintain consistent SLAs, even during unpredictable traffic spikes.
Built-in cost efficiency#
- Autoscaler tracks real ML workload metrics (queue depth, concurrency) rather than CPU utilization for precision scaling.
- Scales to zero during idle periods and blends on-demand and spot instances to minimize cost.
- Delivers 30–50% lower infrastructure spend while keeping GPU utilization high and budgets predictable.
The Bento Inference Platform turns inference from a cost center into a growth driver. It combines open infrastructure, intelligent scaling, and developer-first design to deliver enterprise-grade speed, flexibility, and control that SageMaker can’t match.
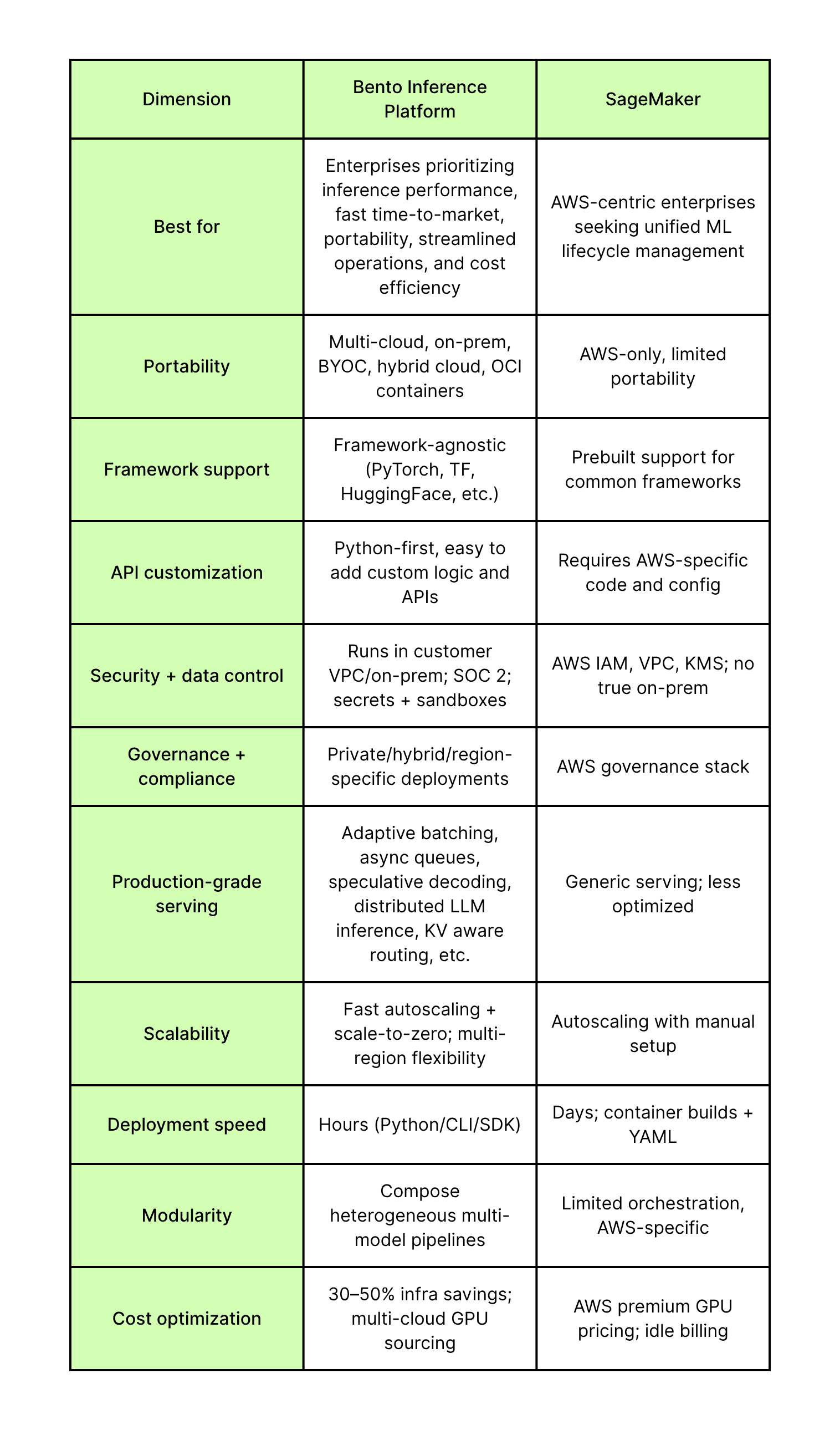
Quick Comparison Matrix: Bento vs. SageMaker#
For enterprise AI leaders, the right platform choice comes down to priorities. SageMaker is designed as a broad AWS-native ML suite, while the Bento Inference Platform is purpose-built for inference.
The table below highlights where each solution is strongest and how they differ across portability, scalability, cost, and operational impact.
Inference at Scale: Real-Time And Batch#
For enterprise AI teams powering chatbots, copilots, or recommendation systems, milliseconds matter. Every inference request must scale instantly, deliver consistent latency, and use compute efficiently.
That’s where the difference becomes clear: SageMaker treats inference as one of many ML lifecycle components, while Bento is built to optimize it.
SageMaker: Complexity, cost, and slow iteration#
SageMaker’s inference layer relies on manual configuration for scaling and workload management.
Teams must set autoscaling thresholds, manage container instances, and balance between overprovisioning (to avoid latency) and idle costs (when demand drops). The result: unpredictable spend and operational inefficiency.
- Manual scaling overhead: Engineers tune instance counts and policies instead of deploying models.
- Idle GPU costs: Always-on endpoints bill even when inactive, driving unnecessary cloud spend.
- Slow deployment cycle: YAML-heavy configurations, container builds, and CloudWatch integrations extend deployment time from hours to days.
For enterprises, these limitations make it difficult to meet real-time performance SLAs or run cost-efficient batch inference at scale.
Bento Inference Platform: Speed, flexibility, and predictable scaling#
The Bento Inference Platform eliminates that operational drag with fast autoscaling and a developer-first workflow. It supports both real-time inference for interactive applications and batch inference for scheduled workloads within one serving framework.
- Adaptive batching for performance: Dynamically adjusts batch size and latency windows in real time to balance throughput and responsiveness.
- Scale-to-zero efficiency: Automatically spins down idle resources and spins them up instantly as new requests arrive, cutting idle GPU costs without compromising performance.
- Python-first deployment: Expose an inference API in a few lines of code with decorator-based syntax. No YAML, no container rebuilds, deploy in hours, not days.
These capabilities deliver faster iterations, lower costs, and consistent SLAs, advantages that are already proven in production.
For example, Neurolabs, a computer vision company serving global consumer brands, reduced compute costs by 70% and accelerated time-to-market by nine months after switching from SageMaker to the Bento Inference Platform.
With features like adaptive batching and scale-to-zero, their team now deploys new models daily without expanding infrastructure resources.
By removing scaling complexity and automating resource management, Bento enables enterprises to focus on model innovation, not infrastructure maintenance. The result is predictable latency, efficient GPU utilization, and reliable throughput across any workload.
Composing Complex AI Workflows#
Modern AI applications rarely depend on a single model. Enterprises combine multiple components to create multi-stage inference pipelines: LLMs for reasoning, embedding models for semantic search, rerankers for retrieval optimization, and classical ML models for scoring or prediction.
These compound systems power use cases like AI agents, retrieval-augmented generation (RAG), personalization engines, and fraud detection. Managing and scaling such heterogeneous workflows efficiently is one of the biggest operational challenges enterprise AI teams face.
SageMaker: Rigid orchestration and AWS-bound workflows#
SageMaker provides orchestration tools for model deployment, but they remain tightly coupled to the AWS ecosystem. Every pipeline must be defined using AWS-specific services such as Step Functions and SageMaker Pipelines, making setup verbose and difficult to maintain.
- Complex orchestration: Building and managing pipelines requires YAML-heavy configurations and AWS-specific SDKs.
- Limited interoperability: Integrating non-AWS tools or open-source frameworks adds complexity and maintenance overhead.
- Performance bottlenecks: Multi-model endpoints often compete for limited GPU memory, leading to latency spikes and unpredictable throughput.
For enterprises that rely on a mix of open-source and proprietary tools, or that need flexible deployment options across environments, SageMaker’s rigidity can increase operational costs and slow iteration.
Bento Inference Platform: Modular, portable, and built for complexity#
The Bento Inference Platform makes complex, multi-model workflows simple to build, scale, and maintain. It’s designed to let enterprises compose distributed inference pipelines across any environment — cloud, on-prem, or hybrid.
- Distributed services across CPU and GPU: Run preprocessing on CPUs and heavy model inference on GPUs, maximizing hardware utilization.
- Seamless model chaining: Connect heterogeneous models (LLMs, embeddings, rerankers, or classical ML) through lightweight APIs. No custom glue code or rigid orchestration required.
- Infrastructure flexibility: Deploy Kubernetes-native on EKS, GKE, AKS, or bare-metal clusters; integrate easily into existing enterprise stacks.
- Portable by design: Built on the open-source BentoML framework, workloads are packaged in standard OCI containers and run anywhere, eliminating lock-in and reducing migration risk.
This architecture gives enterprises a single operational model for inference that scales globally while meeting regional compliance and data sovereignty requirements.
A leading fintech company exemplifies the difference. Their engineering team initially relied on SageMaker but found it too restrictive for complex, stateful services that integrated with internal databases and business logic. After moving to Bento, they achieved seamless portability across EKS and multi-cloud environments, cutting maintenance overhead and fragility while accelerating deployment cycles.
By simplifying workflow composition and ensuring full portability, Bento helps enterprises innovate faster, lower operational costs, and future-proof their inference infrastructure.
Turn Inference Into Your Competitive Advantage#
For enterprise AI teams, choosing an inference platform is a strategic decision. The right platform determines how quickly your organization can launch AI products, scale reliably, and control infrastructure costs.
AWS SageMaker offers broad ML lifecycle management, but its inference layer isn’t specialized. As workloads scale, this results in slower iteration, higher costs, and tighter vendor dependency.
The Bento Inference Platform takes a different approach. Purpose-built for production inference, it streamlines deployment and scaling through automation, multi-cloud portability, and a developer-friendly Python-first workflow.
By abstracting container management and manual scaling logic, enterprises can launch faster, manage budgets predictably, and grow without expanding headcount. Yext demonstrates these results: by migrating to Bento, the company cut development time by 70%, reduced compute spend by 80%, and doubled model output, now running over 150 models in production globally.
When inference directly impacts performance, cost, and agility, Bento delivers a clear competitive edge.
Schedule a call with us to see how your team can achieve the same outcomes.