Inference Platform: The Missing Layer in On-Prem LLM Deployments
Authors


Last Updated
Share

⚠️ Note: Bento is now part of Modular! Schedule a call with us to learn how Bento and Modular can help you serve high-performance inference in production.
At Bento, we work closely with enterprises across industries like healthcare, finance, and government. Many of them choose to move LLM workloads into on-prem environments, and for good reasons:
- Data privacy & compliance. LLMs now power critical applications like AI agents and RAG pipelines. These systems often need direct access to sensitive data, making privacy and compliance non-negotiable. Running inference on-prem keeps both data and models entirely within a controlled environment.
- Consistent and reliable performance. Dedicated resources ensure low-latency, predictable responses, without relying on external APIs or shared cloud infrastructure. AI teams can fully control, customize, fine-tune, and integrate models with internal systems.
- Cost reduction. While initial setup requires high investment, on-prem deployments can become far more cost-effective than usage-based cloud APIs in the long run.
But here’s the catch: setting up an on-prem LLM stack isn’t just about buying GPUs and running vLLM on Kubernetes. The real challenge lies in everything that comes after: scaling workloads, maximizing GPU utilization, optimizing performance, and serving models reliably in production.
And that’s where most AI teams discover a missing piece in the stack.
The modern on-prem stack for LLM deployments#
To run LLMs on-prem, you need to orchestrate a reliable, scalable, and efficient inference stack, which entails three core layers working together:
-
Infrastructure layer: This is the physical foundation that powers your system, including servers, GPUs, networking, storage, power, and cooling.
-
Container orchestration layer: Platforms like Kubernetes and OpenShift manage containerized workloads, schedule jobs, and balance resource usage across nodes. This layer abstracts the underlying hardware and provides deployment primitives for your system.
-
Inference platform layer: This is the often-overlooked part where things fall short. It:
- Manages model deployments and iterations
- Optimizes inference performance, with different runtimes and distributed serving strategies, like prefill-decode disaggregation and KV aware routing
- Handles autoscaling and optimizes cold starts & resource utilization
- Provides observability for LLM performance metrics and costs
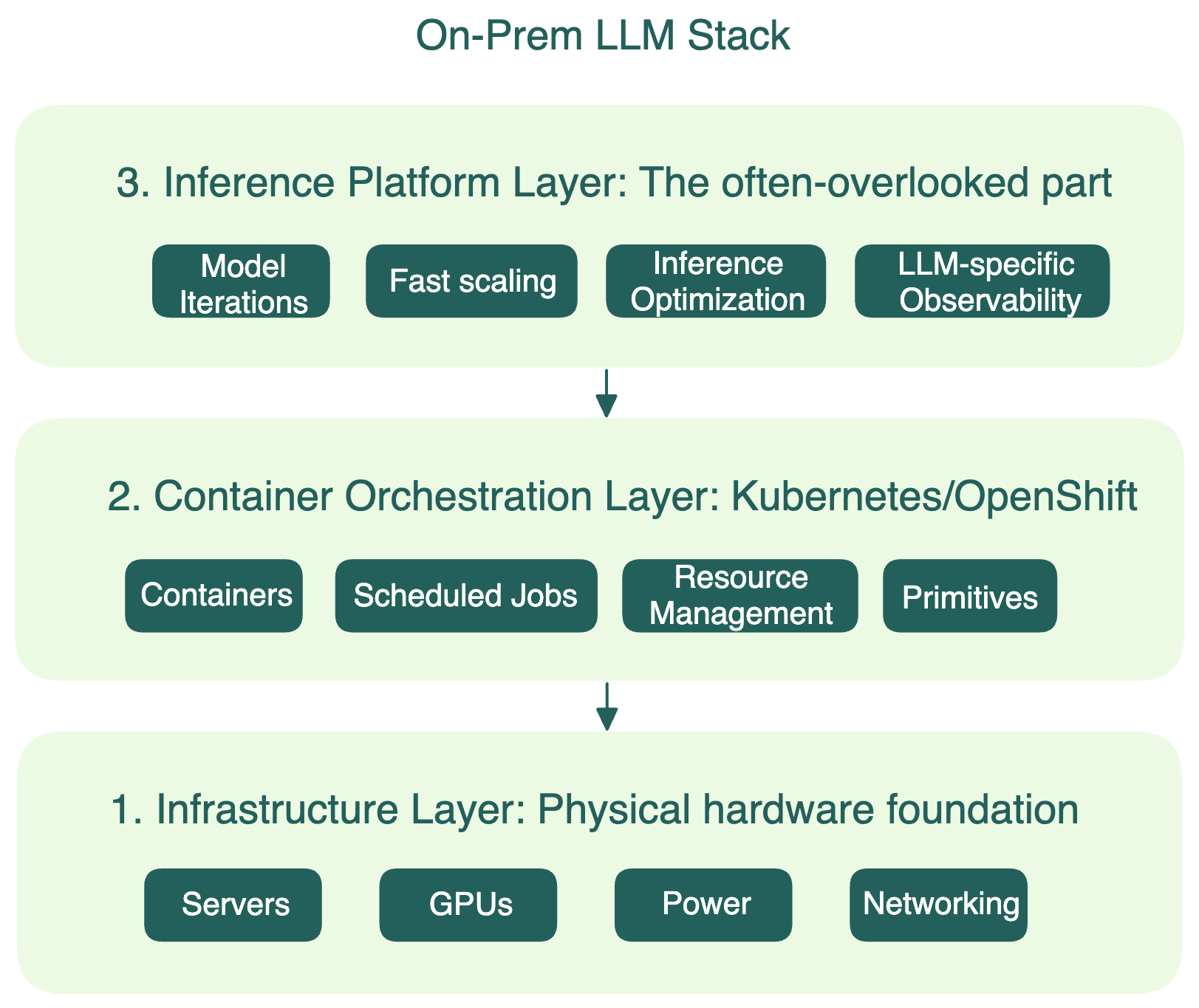
Most organizations already have layers 1 and 2 in place. Layer 3 matters for long-term scaling but it’s often missing or built ad hoc.
Risks of on-prem LLM deployments and how an inference platform can help#
Moving LLMs on-prem promises better control and cost efficiency, but it also shifts more responsibility to your infrastructure/platform team. Let’s break down the most common pain points and how an inference platform helps solve them.
1. Slow time to market#
LLMs are evolving rapidly. New frontier models and inference optimization techniques are released constantly. As a result, AI teams are under pressure to evaluate and deploy them quickly. But turning experiments into production-ready services often gets bogged down by manual infrastructure work:
- Packaging models and building container images
- Integrating with the right inference backend
- Tuning performance for specific latency/throughput targets
- Setting up autoscaling, observability, and reliability guarantees
- Implementing custom serving logic or multi-model chaining for advanced agentic systems
If a model needs to be optimized for a specific use case, such as distributed inference or benchmarking, it can add weeks or months to the timeline.
AI teams should be able to ship fast, not dealing with infrastructure issues for every model.
A strong inference platform removes these roadblocks:
- Standardized workflows to deploy and iterate on new models in minutes or hours, not weeks
- SOTA open-source models pre-packaged with different optimization options, deployable with a few clicks
- Built-in support for performance tuning, autoscaling, and observability
- Developer-friendly tools and abstractions for implementing custom logic
Without this layer, projects get stuck in limbo, which means missed market opportunities. Speed is a competitive edge, and an inference platform helps you move faster.
2. Poor cost visibility and GPU utilization#
Many teams turn to on-prem deployments with the goal of reducing long-term costs. However, those cost savings only materialize if you’re using your compute efficiently.
On-prem GPUs are a fixed resource. If they’re sitting idle, or worse — running zombie workloads that no one’s monitoring — you’re burning capital without generating value.
To truly realize the cost benefits of on-prem, you need two things:
- Fast autoscaling to respond to actual traffic patterns. During spikes, workloads should scale up to handle new requests. When idle, they should scale down so resources can be reused for other tasks to maximize ROI.
- Clear visibility into GPU utilization and costs. This ensures you know whether your infrastructure is working efficiently and whether you’re getting the savings you expect.
This is where an inference platform plays a critical role. It provides the autoscaling logic and real-time metrics needed to maximize GPU usage and reduce waste.
The first two layers weren’t designed to handle GenAI workloads like LLMs. They don’t support fast autoscaling for multi-gigabyte LLM container images, or intelligent scheduling based on KV cache availability (higher cache hit rates means better use of techniques like prefix caching to reduce compute costs). The inference layer fills that gap.
3. Performance bottlenecks#
As LLM context windows expand and use cases grow more complex, single-node inference optimizations quickly hit a wall. Techniques like continuous batching can help squeeze more out of a single GPU, but they’re no longer enough.
Modern LLM inference is shifting toward distributed architectures:
- Prefill and decode require different resources. Prefill is compute-intensive, while decode is memory-bandwidth bound and token-by-token. Co-locating both on the same hardware leads to contention and waste. They need separate resources to deliver the optimal performance and scale independently.
- KV caches create memory pressure. Long-context models or agentic systems rely heavily on techniques like prefix caching to accelerate inference and reduce costs. However, storing tons of KV caches consumes significant GPU memory.
- Model sizes exceed single-GPU limits. A 70B parameter model in FP16 needs over 140 GB of memory (not to mention overhead for runtime or KV caches). To serve models at this scale, you need techniques like tensor parallelism and expert parallelism (for MoE models) to split and distribute workloads across multiple GPUs.
Solving these problems means building a distributed inference stack, including disaggregated serving, intelligent routing, and KV cache offloading. However, most AI teams don’t have the time to solve them from scratch in on-prem environments.
This is where a modern inference platform becomes essential. Ideally, it should support the latest distributed inference optimizations out of the box and make them accessible to developers, without needing to reinvent complex infrastructure.
4. Observability challenges#
For LLM workloads in production, especially those with strict SLAs and uptime guarantees, you must have deep, inference-specific observability. But traditional monitoring stacks, which are built for web services and microservices, don’t offer the visibility to operate and optimize LLM workloads.
To ensure reliable inference at scale, you need visibility into LLM-specific metrics and behavior, such as:
- Time to First Token (TTFT), Time per Output Token (TPOT), and Token Generation Time for understanding latency characteristics across different stages of token generation
- Prefix cache hit rate to measure the effectiveness of KV cache reuse and inform routing decisions
- Cost per request or token to analyze and optimize compute cost per unit of work
- Usage tracking and cost analysis broken down by team or project to ensure accountability and identify optimization opportunities
- Prompt filtering, output anomalies, and model behavior drift to monitor output quality and unexpected behavior
These metrics don’t live at the infrastructure or orchestration layers; they live at the inference layer. Without them, teams are left guessing where bottlenecks are or how to tune performance.
A modern inference platform provides LLM-specific observability that helps AI teams optimize performance and maintain reliability over time.
5. Operational inefficiency#
As organizations scale their AI initiatives, inferenceOps quickly become a major source of complexity.
It’s no longer just about serving a single LLM. Enterprises today deploy compound AI systems that combine multiple models: LLMs, embedding models, SLMs, and reasoning models. They power agentic workflows, RAG pipelines, and decision-making tools, which lead to heterogenous AI workflows.
This also means heterogeneous compute requirements. Some models are GPU-bound, others are CPU- or IO-heavy. Managing these different workloads on a shared cluster requires a carefully orchestrated architecture to avoid bottlenecks and maximize efficiency.
But here’s the problem: maintaining these systems and compute resources manually is a massive tax on engineering teams. It diverts attention from core product development and slows down innovation.
What’s needed is a standardized layer that abstracts away the complexity. An inference platform fills that gap. It offers:
- Consistent workflows for deploying and updating models
- Tooling for managing multi-model, multi-team workloads
- Built-in scheduling and resource allocation logic to handle heterogeneous pipelines across multiple on-prem clusters
InferenceOps isn’t just an infrastructure problem; it’s a productivity one. A good inference platform gives teams the tools to ship faster with less friction.
Bento On-Prem: The inference platform layer for modern LLM workloads#
The five risks we outlined above are the biggest blockers for on-prem LLM success. They all stem from one missing piece: the inference platform layer.
That’s exactly where Bento On-Prem comes in.
- Let AI teams move fast with production-ready workflows for deploying, scaling, and managing LLMs.
- Get optimal performance with built-in support for fast autoscaling, distributed serving, and inference-specific observability
- Seamlessly integrate with your existing infrastructure and container orchestration layers
- Keep all data and models fully within your private on-prem environment
Built for speed, simplicity and control, Bento On-Prem lets AI teams move fast without additional complexity to your stack.
Running LLMs on-prem? We’d love to help.
- Contact us today to see how we can help you deploy secure, scalable LLM inference entirely within your control.
- Join our community forum to connect with other teams and chat about secure, scalable LLM deployments.
- Check out our LLM Inference Handbook to learn everything about inference.