The Shift to Distributed LLM Inference: 3 Key Technologies Breaking Single-Node Bottlenecks
Authors


Last Updated
Share

The landscape of LLM inference is rapidly evolving, with a clear shift toward distributed serving.
What’s happening? Single-node GPU optimizations like dynamic batching, paged attention, and CUDA tweaks are starting to show limitations as LLM inference scales. Larger models like DeepSeek-R1 and tasks with longer context, such as reasoning or agentic use cases, stretch the limits even further.
Today, inference optimization is no longer just about squeezing more out of a single node, but rethinking how to distribute inference across a cluster of workers. If you’re working to deploy and scale LLM services, this is a trend you can’t afford to ignore. It heralds a new era, one that brings better resource allocation, smarter GPU usage, lower token latency, and reduced cost per generated token.
Leading AI teams and open-source communities are already pioneering distributed inference strategies. We’ve seen optimization efforts converge on three key areas:
- Prefill-decode (PD) disaggregation
- KV cache utilization-aware load balancing
- Prefix-aware routing
In this blog post, we’ll walk through each of these and highlight the active progress to address the challenges they present.
PD disaggregation#
To understand PD disaggregation, let’s start with how LLM inference actually works.
For transformer-based LLMs, every time you send a prompt, the model goes through two key steps:
- Prefill: Processes the entire sequence in parallel and store key and value vectors from the attention layers in a KV cache. This helps the model efficiently output new tokens later without recomputing everything from scratch. Because it’s handling all the tokens at once, prefill is compute-bound, but not too demanding on GPU memory.
- Decode: Generates the output tokens, one at a time, by reusing the KV cache built earlier. Different from prefill, decode requires fast memory access but lower compute.
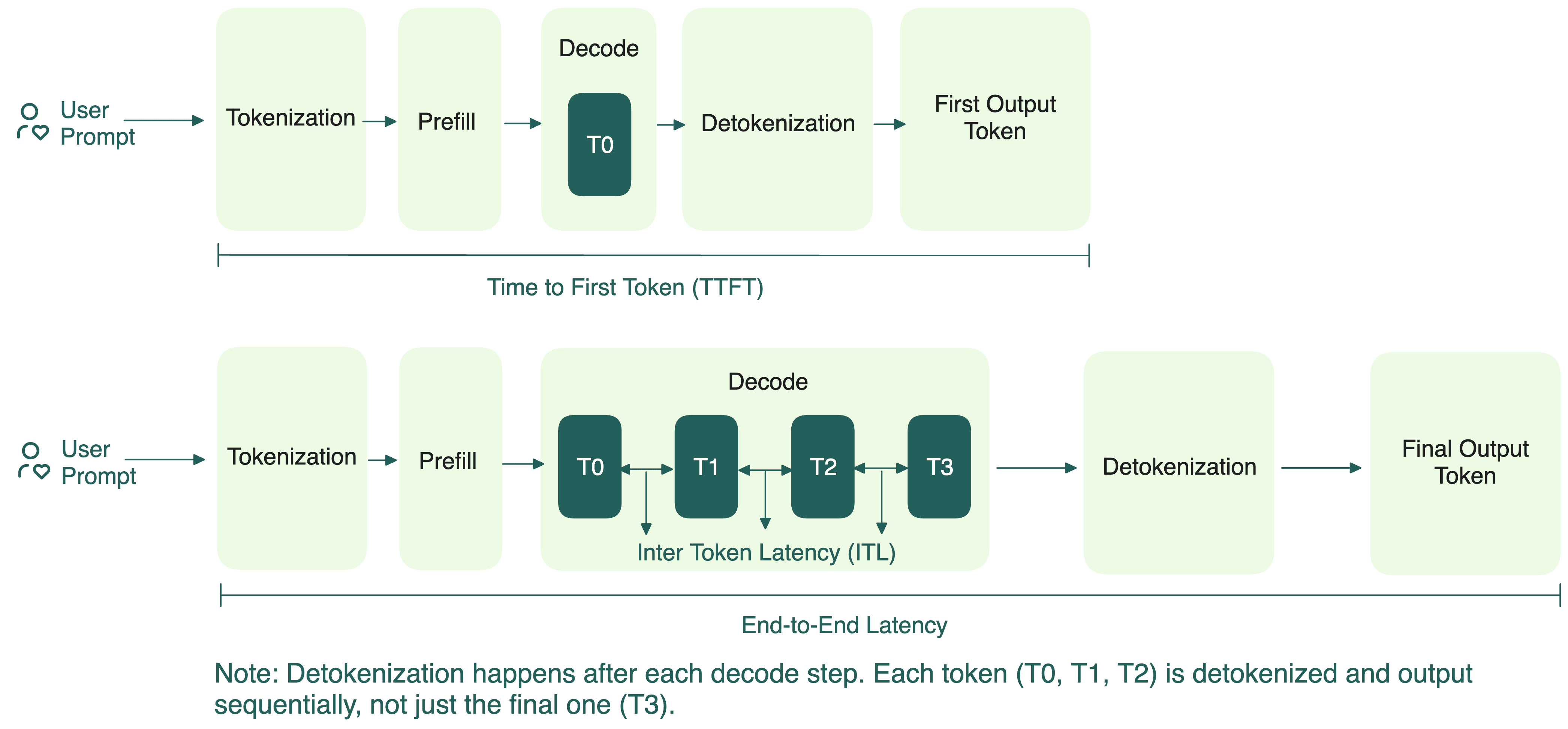
For a long time, the standard way of doing inference was to run these two steps together. On the surface, this might seem straightforward.
In practice, you’ll often have multiple requests arriving at once. Each one has its own prefill and decode needs, but only one phase can run at a time. When the GPU is occupied with compute-heavy prefill tasks, decode tasks must wait, which increases ITL, and vice versa.
Since prefill primarily determines the TTFT and decode impacts ITL, collocating them makes it difficult to optimize both metrics simultaneously.
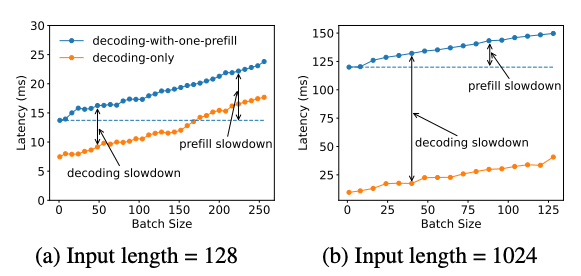
Why disaggregation makes sense#
The idea of PD disaggregation is simple: separate these two very different tasks so they don’t get in each other’s way. Key benefits include:
- Dedicated resource allocation: Prefill and decode can be scheduled and scaled independently on different hardware. For example, if your workload has lots of prompt overlap (like multi-turn conversations or agentic workflows), it means much of your KV cache can be reused. As a result, there’s less compute demand on prefill and you can put more resources on decode.
- Parallel execution: Prefill and decode phases don’t interfere with each other anymore. You can run them more efficiently in parallel, which means better concurrency and throughput.
- Independent tuning: You can implement different optimization techniques (like tensor or pipeline parallelism) for prefill and decode to better meet your goals for TTFT and ITL.
Several open-source frameworks and projects are actively exploring PD disaggregation, including SGLang, vLLM, Dynamo, and llm-d.
Disaggregation isn’t always a silver bullet#
As promising as PD disaggregation sounds, it’s not a one-size-fits-all fix.
-
Thresholds matter: If your workload is too small, or your GPU setup isn’t tuned for this approach, performance can drop (by 20-30% in our tests).
-
Local prefill can be faster: For shorter prompts or when the decode engine has a high prefix cache hit, running prefill locally on the decode worker is often faster and simpler.
-
Data transfer cost: Disaggregation requires moving KV caches rapidly and reliably between prefill and decode workers. This means your solution must support fast, low-latency communication protocols that are both hardware- and network-agnostic. Unless the performance gains from disaggregation outweigh the data transfer cost, overall performance can actually degrade. Existing methods for data transfer for your reference: NVIDIA Inference Xfer Library (NIXL), CXL, NVMe-oF.

KV cache utilization-aware load balancing#
For traditional web applications, load balancing is usually pretty simple. Requests are small, responses are quick, and any backend instance can handle any request equally well. Load balancers can use simple strategies like round-robin to distribute traffic evenly.
But things are completely different for LLM inference. A major factor here is the KV cache built during the prefill phase.
Traditional load balancers treat LLM workers like identical black boxes. They don’t see what’s going on inside each worker, including:
- How much GPU memory is consumed by the KV cache
- How long the request queue is
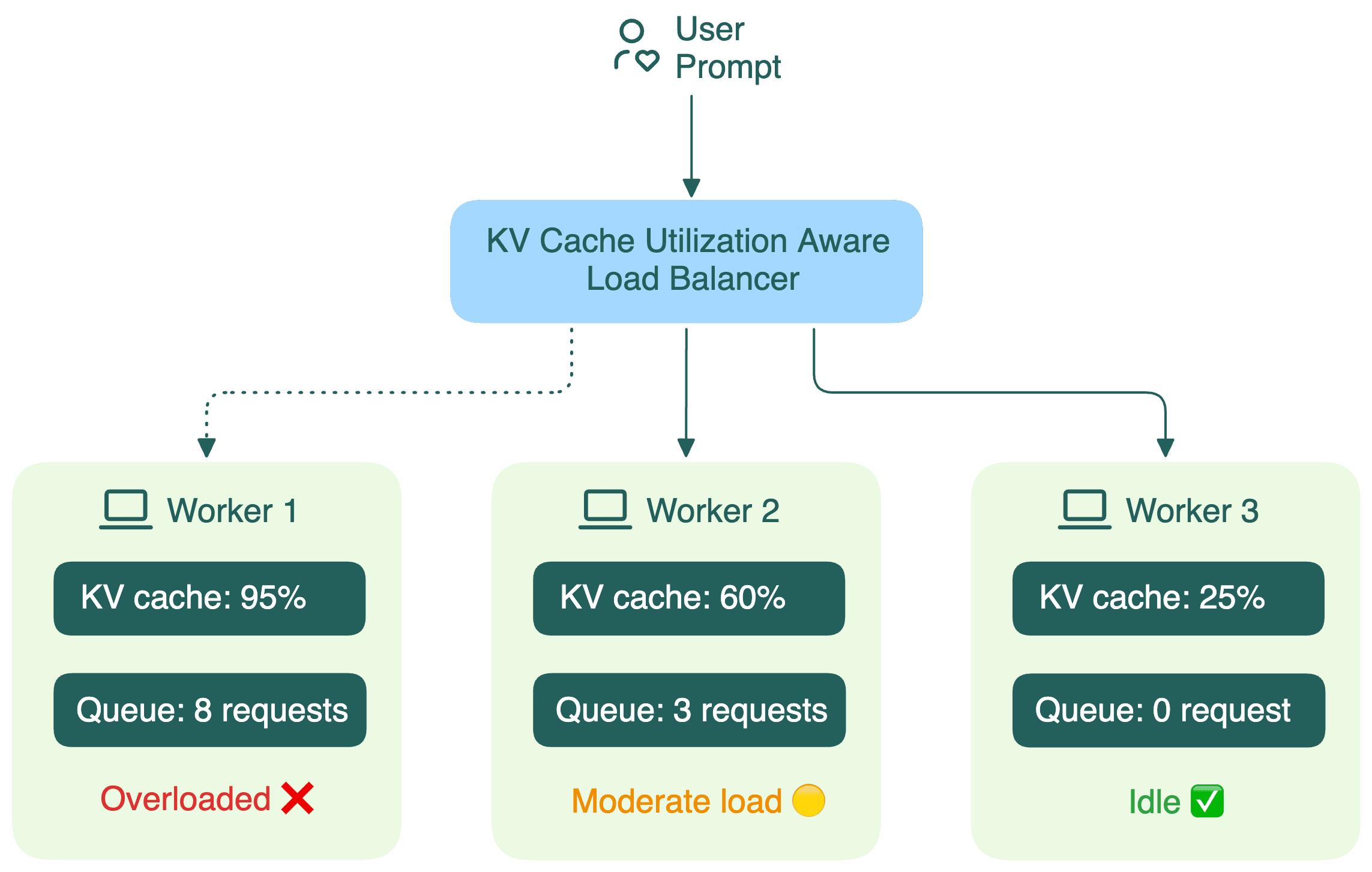
When a load balancer can’t see these details, it starts making bad decisions, leading to:
- Missed cache reuse: New requests with similar prefixes can't leverage existing cached computations (more details in the next section).
- Increased latency: Conversations routed to wrong replicas lose their KV cache, requiring expensive re-computation.
- Load imbalance: Some workers process many long conversations while others remain idle.
The open-source community is already working on smarter solutions. For example, the Gateway API Inference Extension project uses an endpoint picker (EPP) to collect information on KV cache utilization, queue length, and LoRA adapters on each worker, and routes requests to the optimal replica for better inference.
Prefix-aware routing#
The term "KV cache" originally described caching within a single inference request. As mentioned above, LLMs work autoregressively during decode as they output the next new token based on the previously generated tokens (i.e. reusing their KV cache). Without the KV cache, they need to recompute everything for the previous tokens in each decode step, which would be a huge waste of resources.
When extending this caching concept across multiple requests, it’s more accurate to call it prefix caching.
Imagine you have a chatbot system with a prompt like this:
You are a helpful AI writer. Please write in a professional manner.
This system prompt doesn’t change from one conversation to the next. When new messages come in, the model can reuse the stored prefix cache, only processing the new part of the prompt.
Here’s the challenge: How can a new request be routed to the worker that already has the right prefix cached? How does the router know what’s in each worker’s cache?

Different open-source projects are exploring their own approaches:
-
Worker-reported prefix status
Dynamo has workers actively report which prefixes they’ve cached. The router then uses this real-time data to make smart routing decisions.
-
Router-predicted cache status
SGLang maintains an approximate radix tree for each worker based on past requests. This helps the router predict which worker is most likely to have the needed prefix, without constant updates from the workers.
-
Hybrid efforts
-
The Gateway API Inference Extension project is exploring multiple strategies to implement a routing algorithm on EPP:
- Prefix affinity consistent hashing: Group requests with similar prefixes to the same worker.
- Approximate prefix cache on the router: Let the router maintain an approximate lookup cache of the prefix caches on all the backend servers.
- Accurate prefix cache on the router: Gather KV cache information reported by model servers.
-
The llm-d project uses a component called Inference Scheduler to implement filtering and scoring algorithms, and makes routing decisions based on a combination of factors like cache availability, prefill/decode status, SLA and load.
-
Conclusion#
Distributed inference is becoming essential for deploying and scaling LLMs at larger scales. If an enterprise wants to truly optimize for metrics like latency or throughput, distributed LLM inference is the only real path forward. This goes far beyond what serverless API endpoints can achieve.
At Bento, we’re working to ensure our customers and users can tap into these latest LLM inference optimizations. As we’ve seen in our initial experiments, there’s no one-size-fits-all solution. The best approach depends on your specific workloads, models, and what matters most to you (e.g., latency, throughput, or cost).
We’ll be sharing more about distributed LLM inference with detailed benchmarks and best practices in future posts. If you want to collaborate or stay in the loop, feel free to reach out!
- Read our LLM Inference Handbook
- Schedule a call with our experts to discuss how these advanced inference optimizations could fit into your workloads.
- Join our community forum to connect with other builders and get the latest information on LLM inference.
- Sign up for our unified inference platform to deploy and scale cutting-edge open-source LLMs.