Deploying Stable Video Diffusion with BentoSVD
Authors

Last Updated
Share

⚠️ Outdated content#
Note: The content in this blog post is not applicable any more. Please see the BentoML documentation to learn how to deploy Stable Video Diffusion.
The AI industry is advancing at a breathtaking rate. In July, Stability AI unveiled Stable Diffusion XL 1.0, an open-source model for image generation tasks. Only 4 months later, it announced Stable Video Diffusion (SVD), a generative AI model designed to create short video clips from a single static image. It is an image-to-video latent diffusion model, which means it uses a given image as a starting frame (conditioning frame) and then generates a sequence of video frames, resulting in a video clip.
SVD is trained to generate a video sequence of 14 frames at a resolution of 576x1024 pixels, using the same-sized image as the context. The model also comes with a variant featuring a standard frame-wise decoder to ensure the generated video has a more coherent flow over time. Its extension, SVD-XT, which stretches the canvas further, is capable of rendering a 25-frame sequence, thus paving the way for more advanced video creations. Similarly, it comes with a frame-wise decoder for better consistency.
These models provide new opportunities for animation, film pre-visualization, digital art, and dynamic content generation for advertising and social media. They offer a novel approach to enriching visual presentations, educational materials, and even simulations for training purposes across various sectors.
While the use cases are broad and promising, it's important to note that the technology is only designed for research purposes at this stage. The models also have limitations, such as the short length of generated videos and potential issues with the realism of generated content. More importantly, every time a new open-source AI model comes out, it always poses a challenge that every AI application developer needs to face - how to serve and deploy such models in production.
To help you deploy SVD models, we created this sample project BentoSVD with all the example code and dependencies already prepared for you. By following the steps in this blog post, you can:
- Download SVD models
- Serve an SVD model locally
- Build an SVD Bento, which is the standard distribution format in the BentoML ecosystem
- Deploy the Bento in production using BentoCloud for better management, scalability, and observability
Before you begin#
Clone the BentoSVD repository and navigate to the project directory:
git clone https://github.com/bentoml/BentoSVD cd BentoSVD
Key files in this project include:
config.py: Specifies the SVD model that you want to download and use to launch a server to create short videos.requirements.txt: Dependencies required to run this project, such as BentoML.import_model.py: A script to import SVD models into your BentoML Model Store.service.py: The BentoML Service definition, which specifies the input and output logic for an API endpoint and leverages a custom BentoML Runner to run inference.bentofile.yaml: The build configurations for packaging the SVD model and all associated files into a Bento.
Set up an isolated virtual environment for dependency isolation.
python -m venv bento-svd source bento-svd/bin/activate
Run the following command to install dependencies.
pip install -U pip && pip install -r requirements.txt
Testing the SVD model locally#
It's important to test the behavior of the BentoML Service before building the SVD Bento. The Service uses models.get to retrieve the model defined in this file, so you need to set MODEL_VERSION in config.py. You can choose from svd, svd_xt, svd_image_decoder, or svd_xt_image_decoder, with the default set to svd. Later, the chosen model version will be downloaded and used for launching the server.
# Allowed values for MODEL_VERSION include "svd", "svd_xt", "svd_image_decoder", and "svd_xt_image_decoder" MODEL_VERSION = "svd"
Run the script to download the model specified.
python import_model.py
Upon downloading, the model is registered in the BentoML Model Store, your local repository for managing models. Run bentoml models list to view the model.
bentoml models list Tag Module Size Creation Time clip-vit-h-14-laion:wj65momnsoasljo4 bentoml.pytorch 3.67 GiB 2023-11-28 02:13:19 svd:tsky3dunsoasljo4 bentoml.pytorch 8.90 GiB 2023-11-28 02:12:42
Start a server locally, which is accessible at http://0.0.0.0:3000. I used an Ampere A100 machine with 80 GB of VRAM to run this Service locally, while you should be able to start it with less than 15 GB of VRAM.
$ bentoml serve service:svc 2023-11-28T03:37:46+0000 [INFO] [cli] Environ for worker 0: set CUDA_VISIBLE_DEVICES to 0 2023-11-28T03:37:46+0000 [INFO] [cli] Prometheus metrics for HTTP BentoServer from "service:svc" can be accessed at http://localhost:3000/metrics. 2023-11-28T03:37:47+0000 [INFO] [cli] Starting production HTTP BentoServer from "service:svc" listening on http://0.0.0.0:3000 (Press CTRL+C to quit)
If your machine is not as powerful as A100, you may need to set a longer timeout value so that you can successfully receive the response. In this case, apply custom configuration (timeout set to 300 seconds) by running the following command.
BENTOML_CONFIG=bentoml_configuration.yaml bentoml serve service:svc
Send a request via curl after the server starts. Replace test_image.png in the following command with your own image.
curl -X 'POST' \ 'http://0.0.0.0:3000/generate' \ -H 'accept: video/mp4' \ -H 'Content-Type: multipart/form-data' \ -F 'img=@test_image.png;type=image/png' \ -F 'params={ "fps_id": 6, "motion_bucket_id": 127, "cond_aug": 0.02, "decoding_t": 1, "seed": null }' --output generated_video.mp4
The model was trained to generate 25 frames at resolution 576x1024 given a context frame of the same size. Therefore, I recommend you send an image of the same resolution to get the desired response.
This is the image used in the curl request:

Returned output (leaves blowing and cloud moving):

Building and pushing the Bento#
Since the model is working properly, you can build a Bento for better distribution. bentofile.yaml is already available in the project directory with some basic configurations. You can run bentoml build directly to create a Bento.
$ bentoml build ██████╗ ███████╗███╗ ██╗████████╗ ██████╗ ███╗ ███╗██╗ ██╔══██╗██╔════╝████╗ ██║╚══██╔══╝██╔═══██╗████╗ ████║██║ ██████╔╝█████╗ ██╔██╗ ██║ ██║ ██║ ██║██╔████╔██║██║ ██╔══██╗██╔══╝ ██║╚██╗██║ ██║ ██║ ██║██║╚██╔╝██║██║ ██████╔╝███████╗██║ ╚████║ ██║ ╚██████╔╝██║ ╚═╝ ██║███████╗ ╚═════╝ ╚══════╝╚═╝ ╚═══╝ ╚═╝ ╚═════╝ ╚═╝ ╚═╝╚══════╝ Successfully built Bento(tag="svd-service:vhbdipunssasljo4"). Possible next steps: * Containerize your Bento with `bentoml containerize`: $ bentoml containerize svd-service:vhbdipunssasljo4 [or bentoml build --containerize] * Push to BentoCloud with `bentoml push`: $ bentoml push svd-service:vhbdipunssasljo4 [or bentoml build --push]
Make sure you have already logged in to BentoCloud, then push the Bento to the serverless platform for advanced features like automatic scaling and observability.
bentoml push svd-service:latest
Note: Alternatively, run bentoml containerize svd-service:latest to create a Bento Docker image, and then deploy it to any Docker-compatible environment.
On the BentoCloud console, you can find the uploaded Bento on the Bentos page.
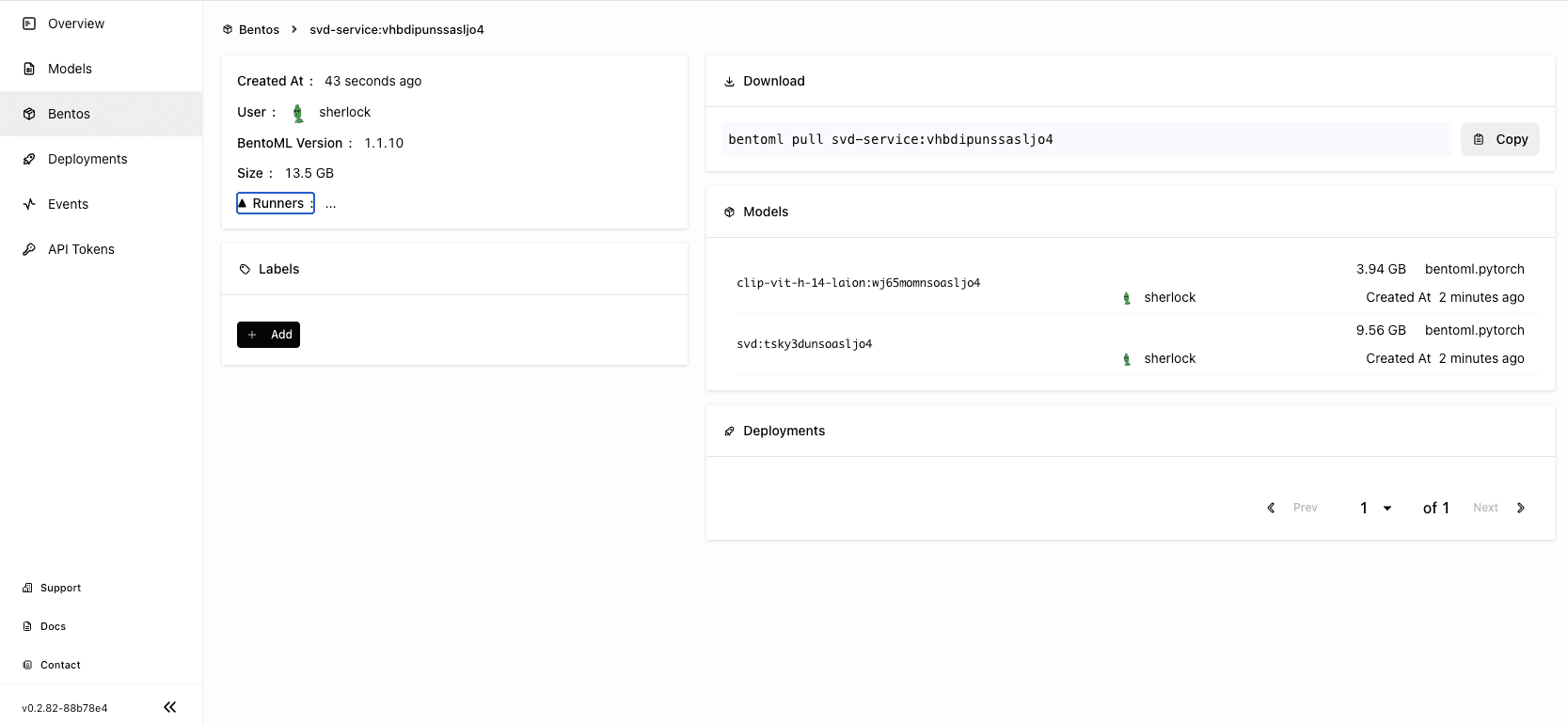
Deploying SVD on BentoCloud#
With the Bento pushed to BentoCloud, you can deploy it via the BentoCloud console. Perform the following steps:
-
Navigate to the Deployments page and click Create.
-
Select On-Demand Function, which is useful for scenarios with loose latency requirements and sparse traffic.
-
Specify the required fields for the Bento Deployment on the Advanced tab and click Submit. Pay attention to the following fields:
-
Instance: As I mentioned above, the VRAM requirement of the SVD model should be less than 15GB. I recommend you select machines like gpu.t4.xlarge, gpu.a10g.2xlarge or gpu.l4.2xlarge for the Runner. Ensure that the instance you select matches or surpasses this specification to avoid performance bottlenecks.
-
Timeout: This is the maximum duration to wait before a response is received. I suggest you set the timeout of both the API Server and the Runner to 300 seconds. This property defaults to 60 seconds, which may fall short if your instance has limited VRAM. Based on our tests, the SVD model’s response time varied across different hardware settings:
- L4: About 3.5 minutes
- T4: About 3.5 minutes
- A10G: About 1.5 minutes
- A100G: About 0.5 minutes
-
BentoML Configuration. Add the following in this field to set the timeout environment variables.
runners.traffic.timeout=300 api_server.traffic.timeout=300
For more information about other properties, see Deployment creation and update information.
-
-
Wait for the application to be up and running.
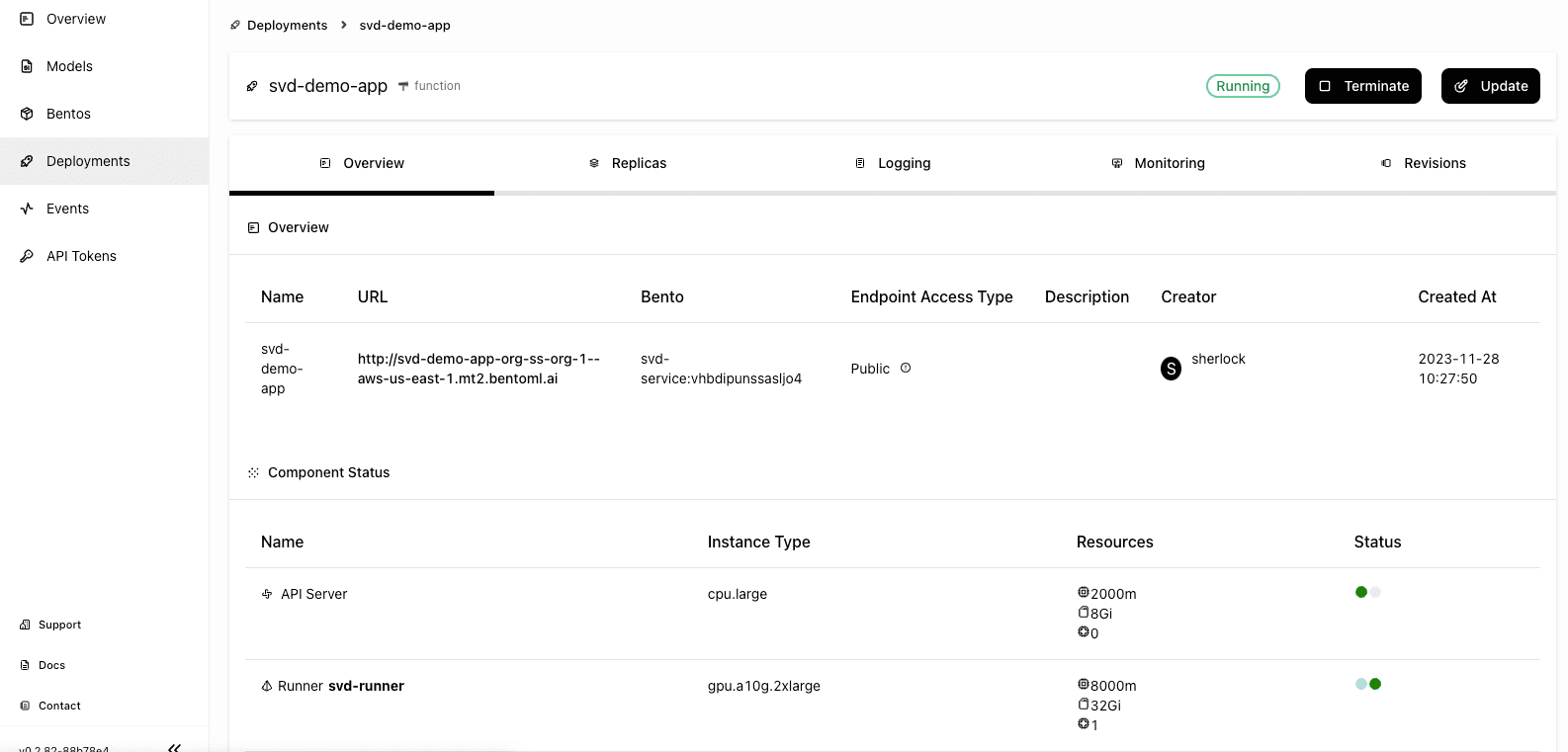
-
The exposed URL is displayed on the Overview tab. Similarly, you can send a request via
curl. Remember to replace the endpoint URL and the image in the command below with your own.curl -X 'POST' \ 'https://svd-demo-app-org-ss-org-1--aws-us-east-1.mt2.bentoml.ai/generate' \ -H 'accept: video/mp4' \ -H 'Content-Type: multipart/form-data' \ -F 'img=@girl_image.png;type=image/png' \ -F 'params={ "fps_id": 6, "motion_bucket_id": 127, "cond_aug": 0.02, "decoding_t": 1, "seed": null }' --output generated_video.mp4This is the image sent in this request:

Returned video:

-
View the application’s performance metrics on the Monitoring tab.
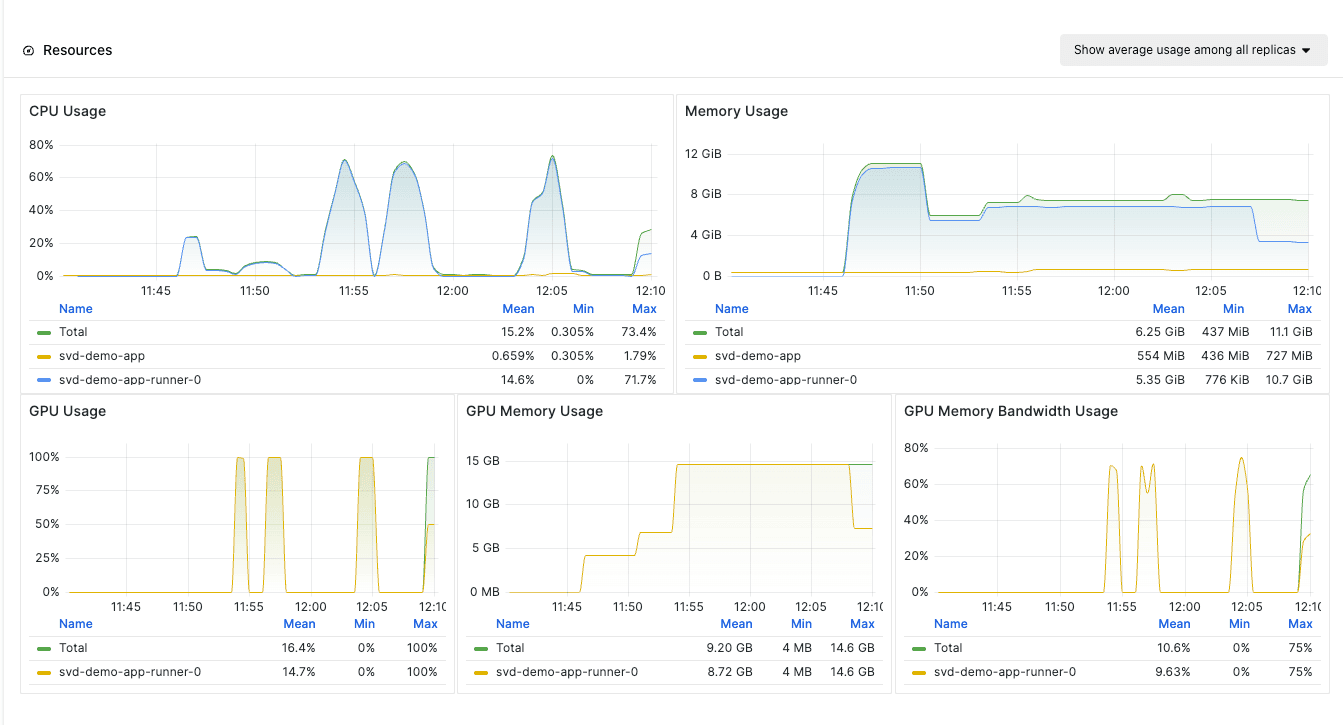
Conclusion#
The field of AI is ever-evolving, and the step from a static image to a dynamic video with the help of a new open-source model is just a part of this journey. With each new model coming to the open-source community, we may encounter both opportunities and challenges. What remains unchanged is that we need an efficient tool to easily create AI applications around these sophisticated models, and BentoML stands out in this landscape. If you want to find out more, I invite you to dive in, experiment with the SVD models, explore the conveniences of BentoCloud, and contribute to the different example projects of BentoML.
Happy coding! ⌨️
More on BentoML#
To learn more about BentoML and its ecosystem tools, check out the following resources:
- [Blog] Deploying Code Llama in Production with OpenLLM and BentoCloud
- [Blog] Building and Deploying an Image Embedding Application with CLIP-API-Service
- [Blog] Building and Deploying A Sentence Embedding Service with BentoML
- [Blog] Deploying Stable Diffusion XL on BentoCloud and Dynamically Loading LoRA Adapters
- Don’t miss out on the chance to be an early adopter! BentoCloud is still open for early sign-ups. Experience a serverless platform tailored to simplify the building and management of your AI applications, ensuring both ease of use and scalability.