Deploying Stable Diffusion XL on BentoCloud and Dynamically Loading LoRA Adapters
Authors

Last Updated
Share

⚠️ The OneDiffusion project has been deprecated#
Note: This blog post is not applicable any more. To deploy diffusion models, refer to the BentoML documentation.
About two weeks ago, we open-sourced OneDiffusion, a platform for AI application developers to run any diffusion model in production with ease and speed. As it provides first class support for BentoML, you can easily package your model into a Bento, the standardized distribution format in the BentoML ecosystem. This artifact can then be containerized as a Docker image and deployed to various environments like Kubernetes. Alternatively, you can push it directly to BentoCloud for hassle-free deployment and management.
In this article, I will explain how to combine the power of OneDiffusion and BentoCloud to deploy the Stable Diffusion XL (SDXL) base model and dynamically load LoRA weights to it on BentoCloud.
Note: According to Stability AI, the SDXL base model is a preferable choice over SDXL 0.9 and SD 1.5 and 2.1; it performs significantly better than the previous variants, and the model combined with the refinement module achieves the best overall performance. This is why I chose it for demonstration in this blog post. If you want, you can choose any other SD model and the procedure is the same.
What you need to know: LoRA & BentoCloud#
Before I begin to show you the deployment steps, I would like to briefly talk about LoRA, BentoCloud, and how dynamic loading works in the serverless platform.
One of the highlighted features of OneDiffusion is that it supports fine-tuning models with LoRA adapters. So, what does this mean in particular? In the realm of machine learning, fine-tuning might require extensive adjustments to weights across multiple, if not all, neural network layers. This is not only resource-intensive but also time-consuming. By contrast, LoRA (Low-Rank Adaptation) introduces low-rank parameters into the model, which are learned during the fine-tuning process. This means, instead of adjusting all the weights of the model, only a small set of these new low-rank parameters are adapted. This approach can be seen as creating task-specific heads or adapters that transform the original pre-trained representations, thus making them more suited to the new task. In short, with LoRA adapters, customizing SD models for niche applications becomes not only efficient but also cost-effective.
OneDiffusion supports dynamically loading LoRA adapters (BTW, OpenLLM also supports fine-tuning LLMs with LoRA adapters. Give it a try 😊). This means you can easily switch between different LoRA weights optimized for various tasks without restarting or reinitializing the entire model. This makes the platform more adaptable and user-friendly.
Now that you have a basic understanding of LoRA, let’s shift our gaze to deployment. As I mentioned in the OneDiffusion release blog post, serving diffusion models like SDXL often demands heavy computational resources, making production deployment a challenging task. This is why you may want to consider BentoCloud to deploy diffusion models. In my previous blog post Deploying Llama 2 7B on BentoCloud, I already showed you running LLMs like Llama 2 in production can be as easy as a few commands and clicks. With BentoCloud, the hassle of infrastructure management fades away, with the serverless platform shouldering the responsibility – be it for diffusion models or others.
So, how does BentoCloud facilitate dynamic loading of LoRA weights? When using OneDiffusion locally, you can specify the LoRA weights path by using the --lora-weights flag or adding the lora_weights field with your prompt. To extend this functionality to BentoCloud, it's essential to package these weights within the Bento pushed to BentoCloud. This ensures the SDXL application can access the LoRA adapters during request processing, a procedure I will delve into later.
Before you begin#
Make sure you meet the following prerequisites.
- Install OneDiffusion by running
pip install onediffusion. - You have a BentoCloud account. BentoCloud is still available for early sign-up and we’ve begun granting access to early adopters.
- Prepare some LoRA weights. For your reference, I will use these two files - H. R. Giger SDXL 1.0 art style lora (
g1g3r.safetensors) and Frank Frazetta SDXL 1.0 art style lora (fr4z3tt4.safetensors) in this article.
Building a Stable Diffusion XL Bento#
-
First, log in to BentoCloud. This requires you to have a Developer API token, which allows you to access BentoCloud and manage different cloud resources. See the BentoCloud documentation to learn more.
bentoml cloud login --api-token <your-api-token> --endpoint <your-bentocloud-endpoint> -
After you log in, run the following command to build a Bento and use the
--lora-diroption to specify the directory where LoRA files are stored.onediffusion build stable-diffusion-xl --lora-dir "/path/to/lorafiles/dir/"If you only have a single LoRA file to use, run the following instead:
onediffusion build stable-diffusion-xl --lora-weights "/path/to/lorafile"By default, the
text2imagepipeline is used when you build a Bento. You can use the--pipelineoption to create a SDXL application with theimg2imgpipeline as follows:onediffusion build stable-diffusion-xl --pipeline "img2img" -
Push your Bento to BentoCloud. You can retrieve the
BENTO_TAGof your Bento by runningbentoml list.bentoml push BENTO_TAG -
After the Bento has been uploaded to BentoCloud, you can find it on the Bento Repositories page. Following is the details page of the Bento.
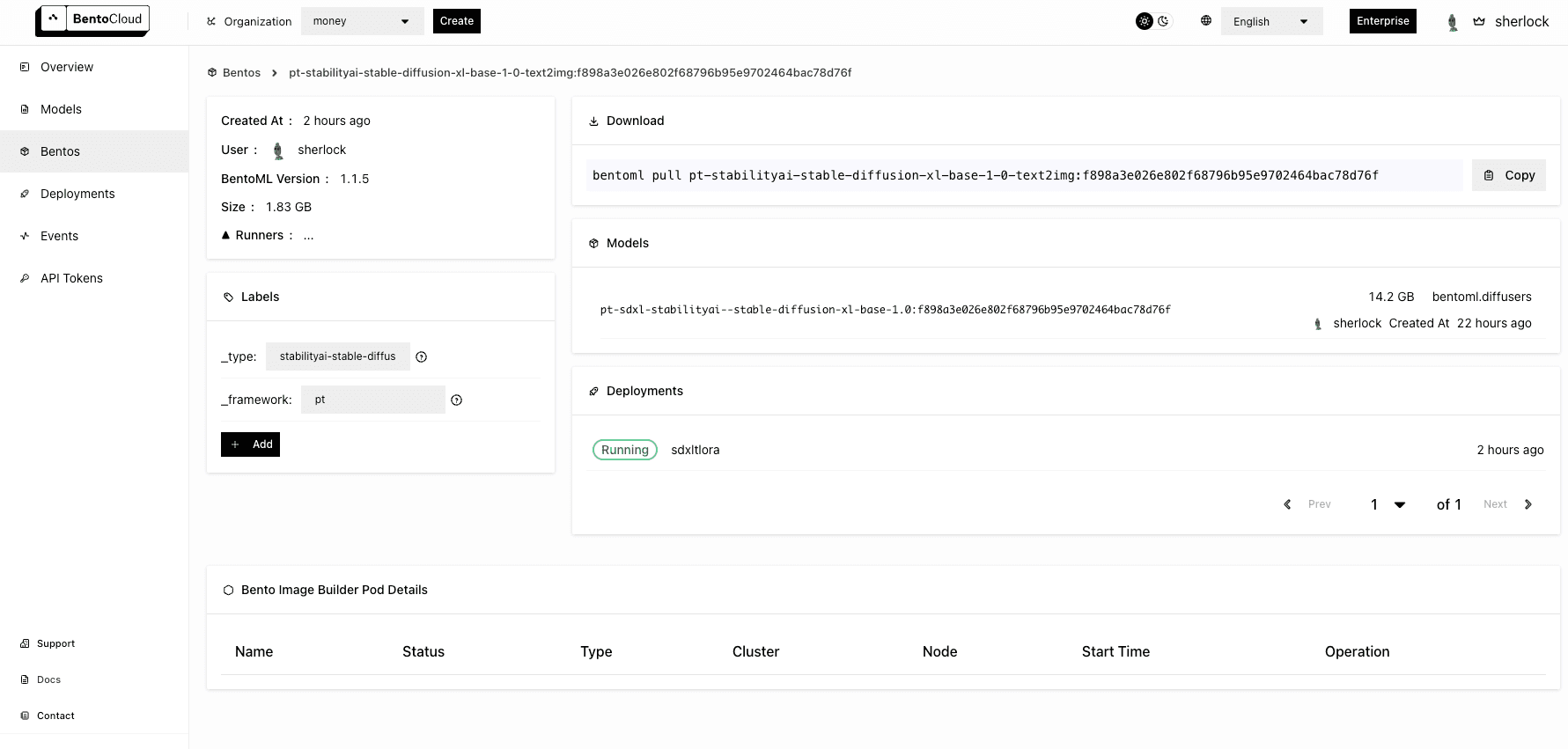
Deploying SDXL on BentoCloud#
With the Bento pushed to BentoCloud, you can start to deploy it.
-
Go to the Deployments page and click Create. Select On-Demand Function as the application type, which is useful for creating generative art images.
-
Set up the Bento Deployment using the Basic, Advanced or JSON tab. Specify all the necessary fields and click Submit when you are done. Note that this SDXL application does not require you to configure any advanced settings so you can basically use the default values on the Basic tab. For your reference, I selected
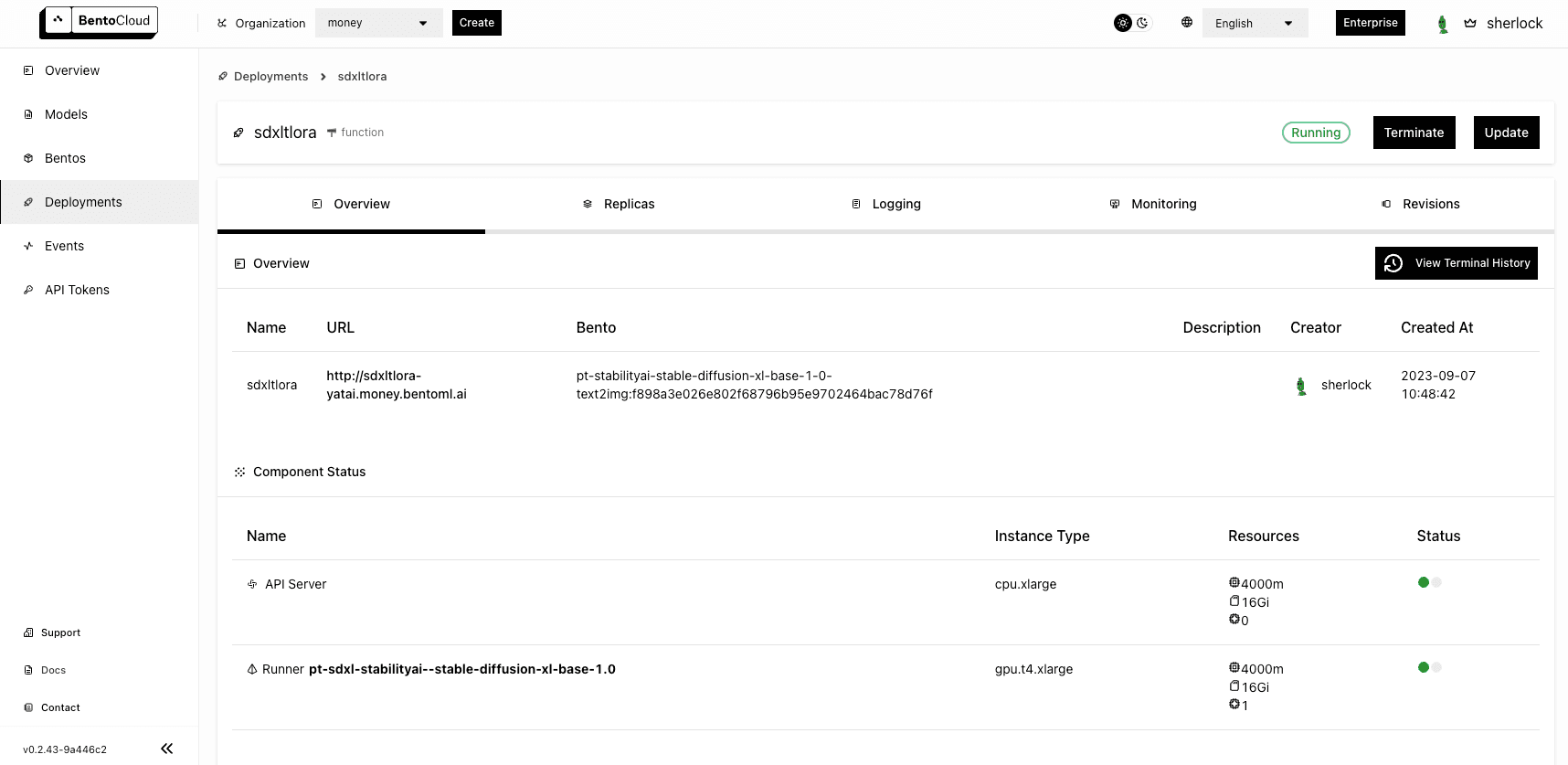
cpu.xlargeandgpu.t4.xlargefor API Servers and Runners respectively. For details of available properties for creating the Deployment, see Deployment creation and update information. -
The deployment may take some time. When it is ready, both the API Server and Runner Pods should be active.
Interacting with the SDXL application#
With the SDXL application ready, you can access it with the URL exposed by BentoML.
-
On the Overview tab of its details page, click the link under URL. If you do not set any access control policy (i.e. select Public for Endpoint Access Type), you should be able to access the link (the Swagger UI) directly.
-
In the Service APIs section of the UI, select the
/text2imageAPI and click Try it out.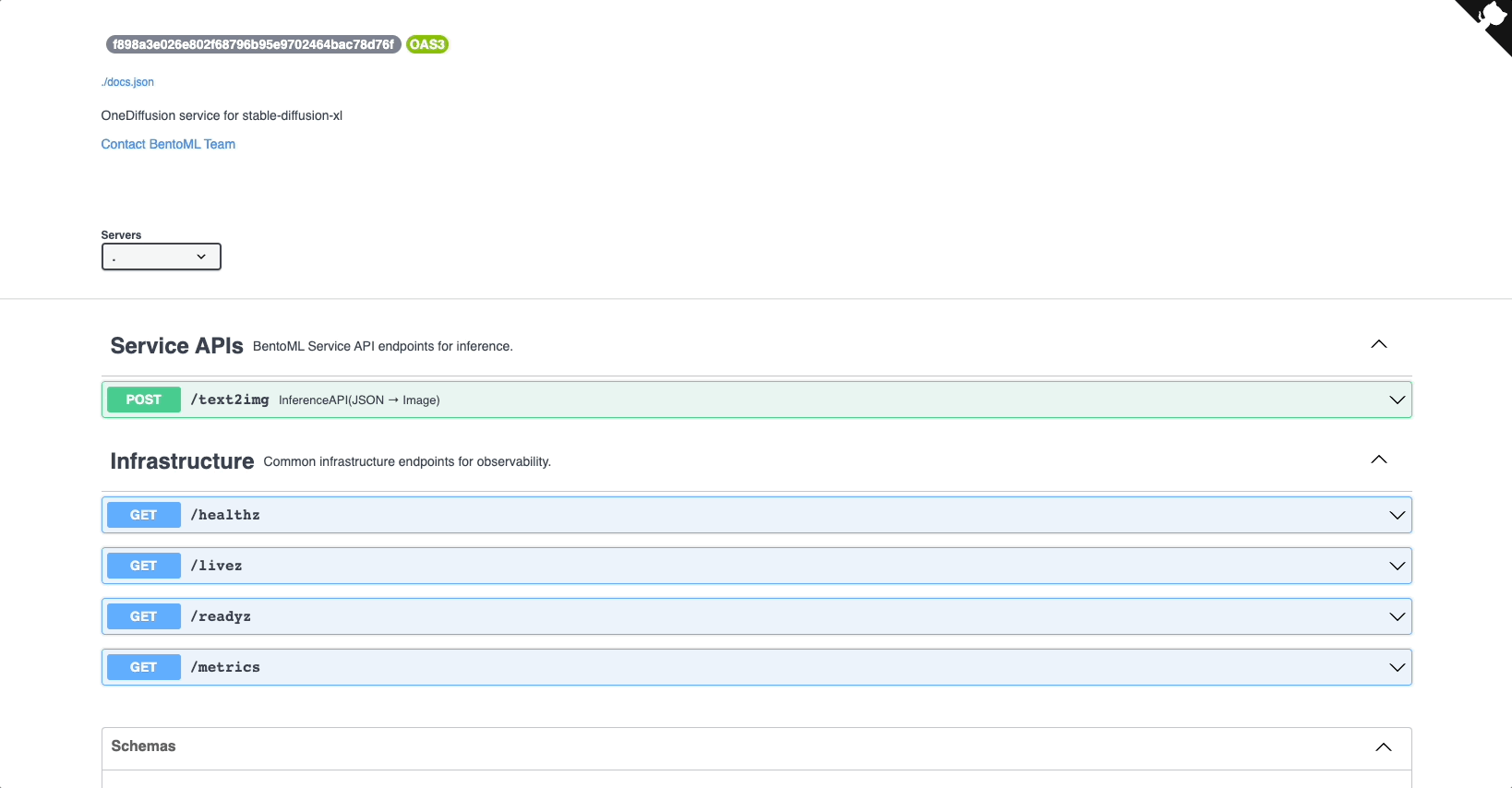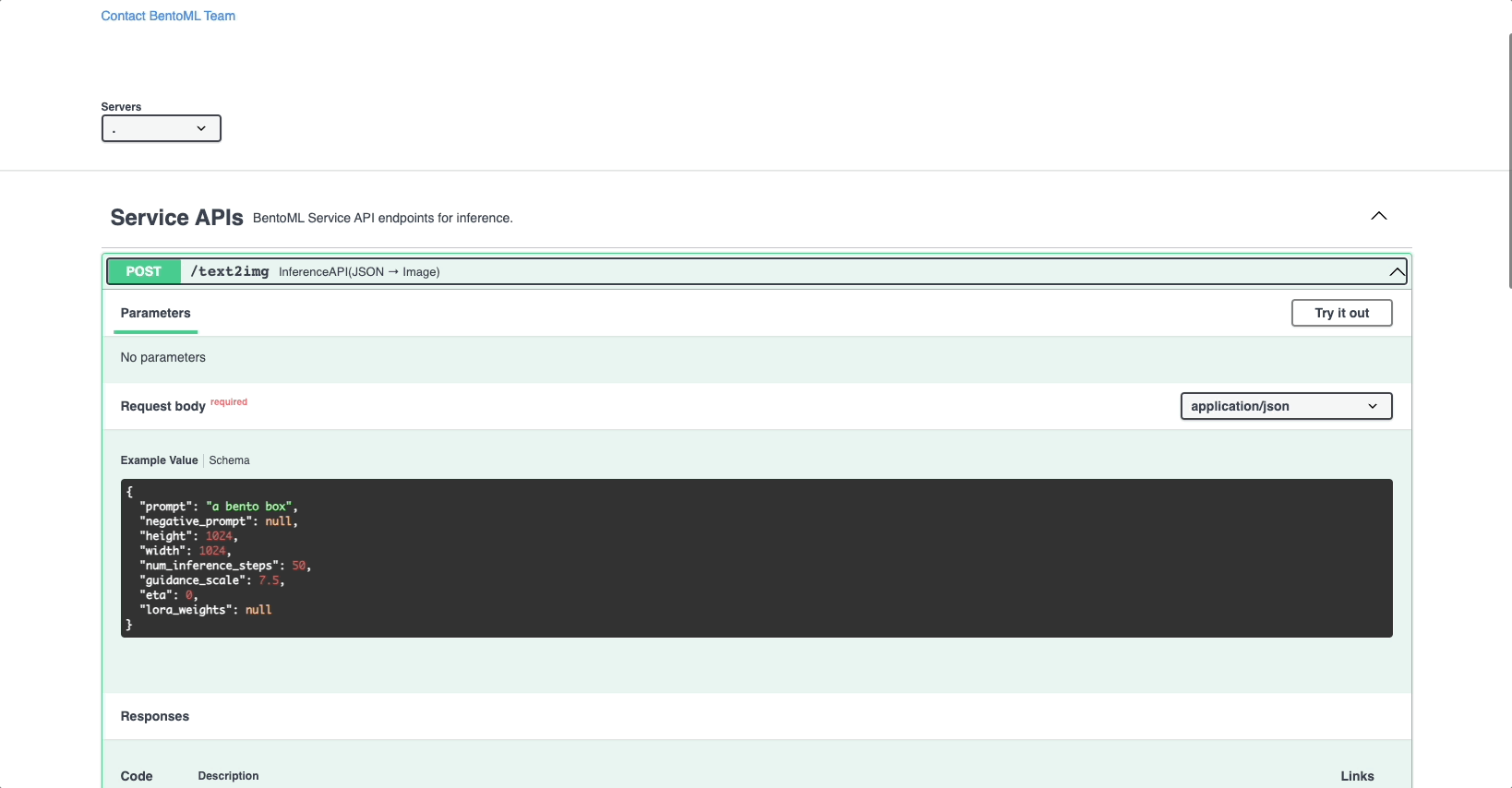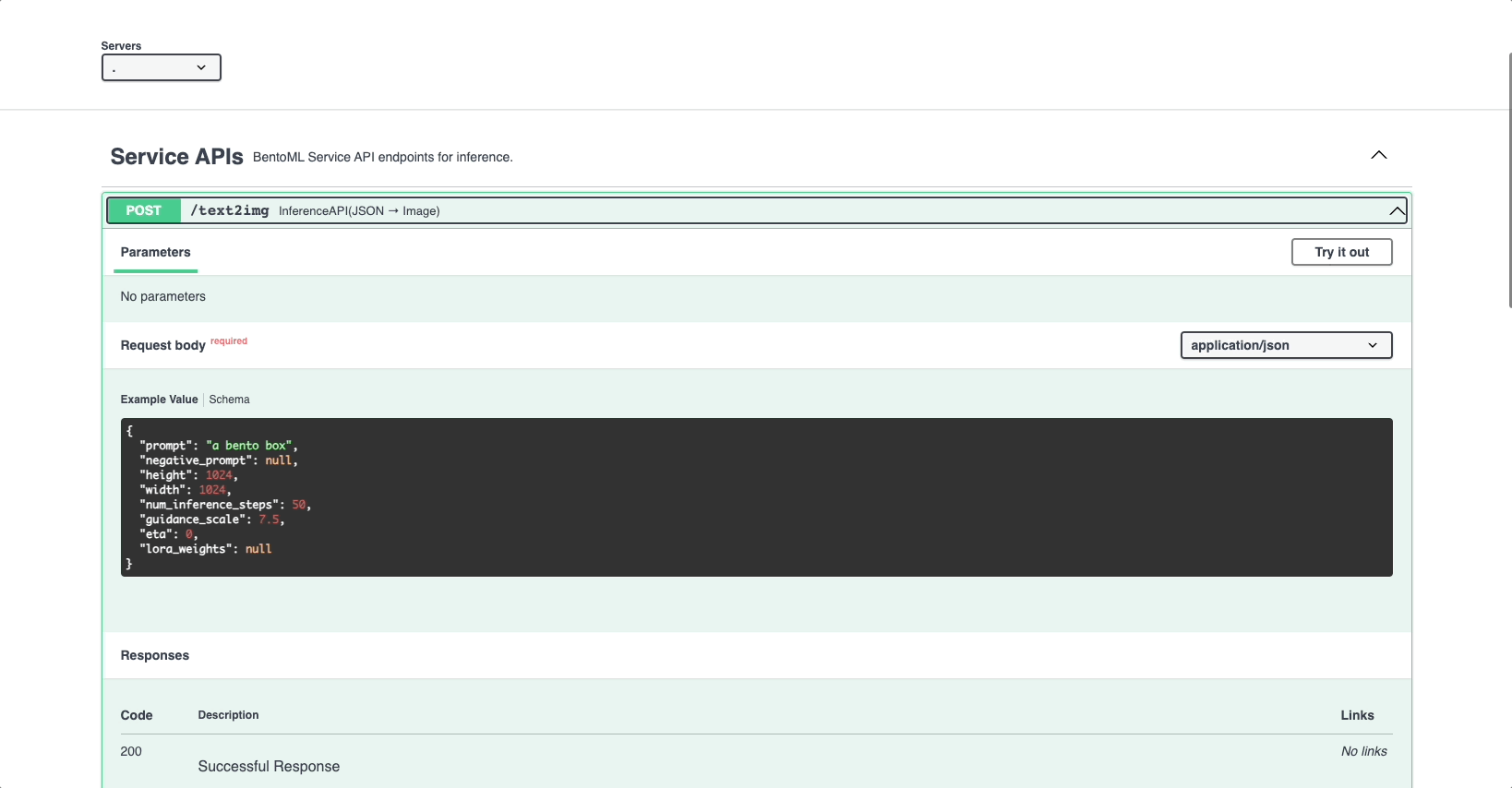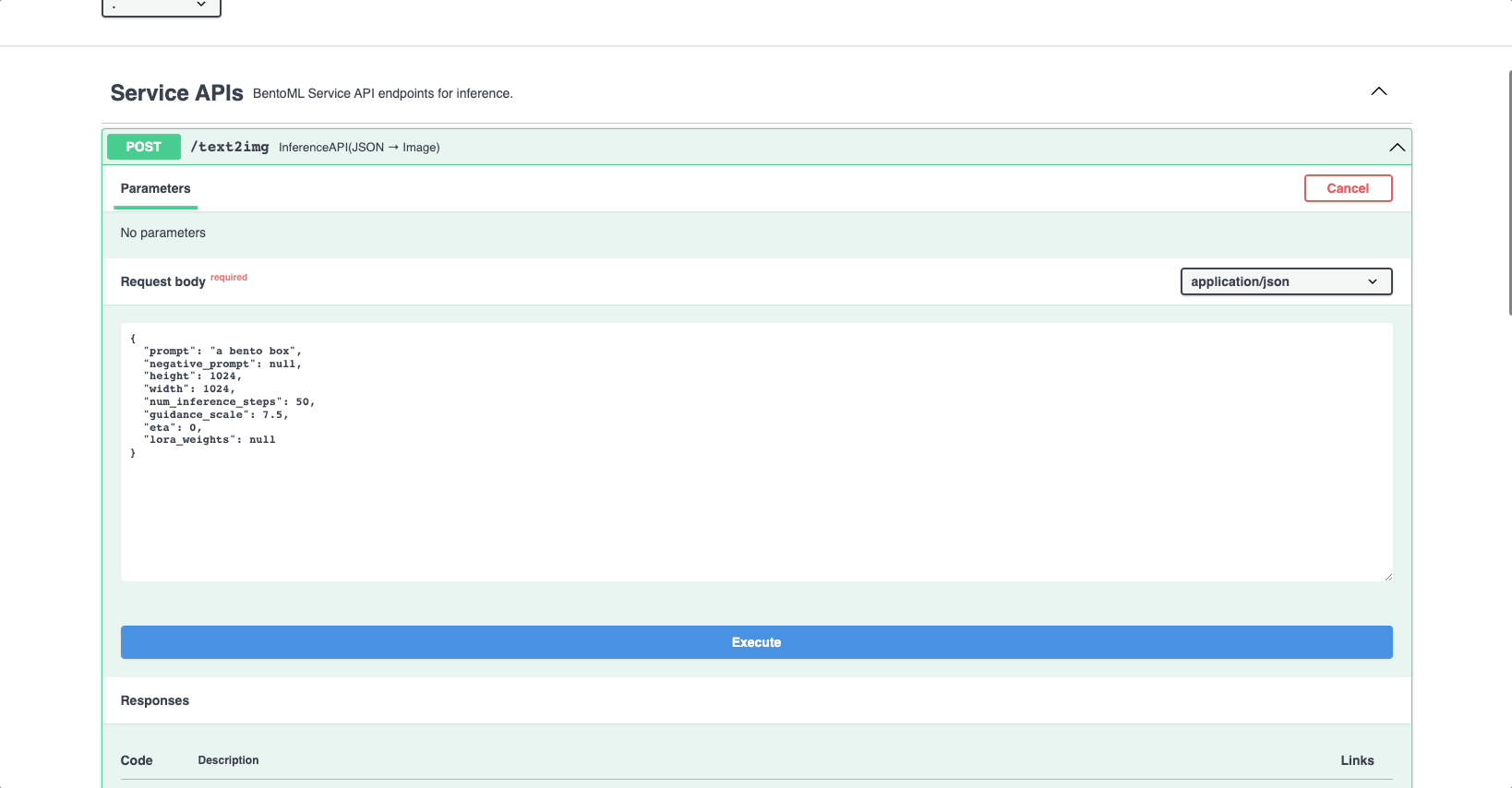
-
First, let’s try creating an image without using any LoRA adapters. Enter your prompt (I used
3t3rnity dark alien architecture machine) and click Execute. Once the image is created, you can find a downloadable file in the Responses section. This is the image returned:
-
Now, let’s load one of the LoRA files
g1g3r.safetensorswith the same prompt by settinglora_weightstog1g3r.safetensors. Click Execute again and here is what I got:
-
Try another LoRA file
fr4z3tt4.safetensorsthis time and the application returns the image below:
-
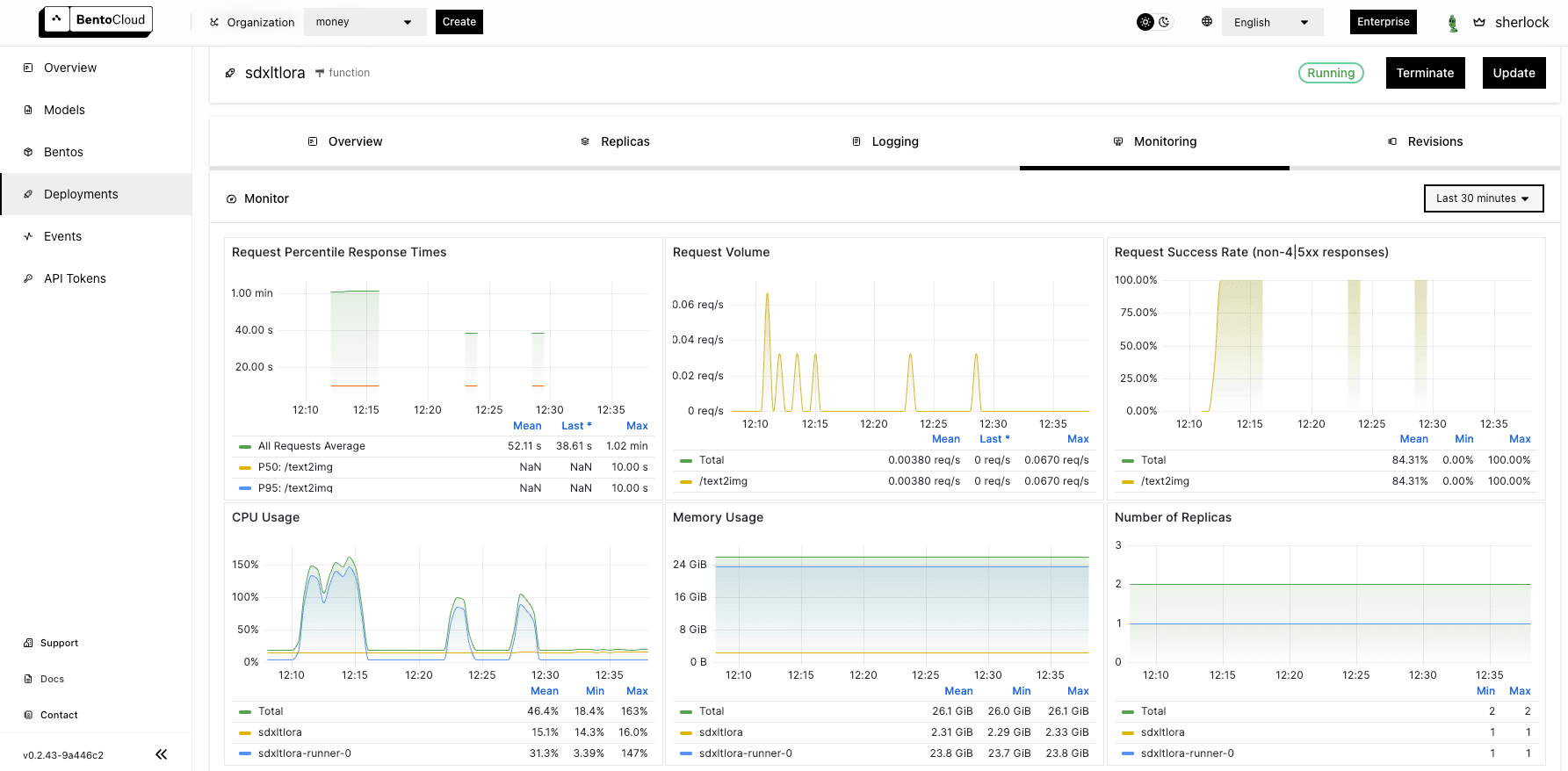
On the Monitoring tab, you can view different metrics of the workloads:
Conclusion#
In this tutorial, I walked you through deploying the Stable Diffusion XL (SDXL) model on BentoCloud with dynamic LoRA weights. By integrating OneDiffusion's ability to handle diffusion models and BentoCloud's deployment capabilities, you can quickly ship their models to production. More importantly, OneDiffusion and BentoCloud's support for dynamic loading of LoRA weights provides greater adaptability, allowing you to easily switch between different styles to create task-specific images without the need for restarts.
Dive in, explore, and happy coding!
More on BentoML and OneDiffusion#
To learn more about BentoML, OneDiffusion, and other ecosystem tools, check out the following resources:
- [Doc] Deploy Stable Diffusion XL with dynamic LoRA adapters
- [Blog] Deploying Llama 2 7B on BentoCloud
- [Blog] Deploying an OCR Model with EasyOCR and BentoML
- Don’t miss out on the chance to be an early adopter! BentoCloud is still open for early sign-ups. Experience a serverless platform tailored to simplify the building and management of your AI applications, ensuring both ease of use and scalability.