Deploying Phi-4-reasoning with BentoML: A Step-by-Step Guide
Authors

Last Updated
Share

Microsoft recently introduced a new family of Phi-4-based reasoning models, bringing advanced reasoning to small language models. Among them, Phi-4-reasoning is a compact 14B model that outperforms much larger models, such as DeepSeek-R1-Distill-Llama-70B, on complex reasoning tasks. It is fine-tuned on chain-of-thought data with curated examples focused on math, science, and coding. This makes it a great fit for:
- Memory- and compute-constrained environments
- Latency-sensitive applications
- Tasks requiring multi-step reasoning and logic
In this tutorial, we'll show you how to self-host Phi-4-reasoning as a private API in the cloud with BentoML.
Setup#
We put everything required for deploying Phi-4-reasoning in this GitHub repository, which contains examples of serving popular open-source LLMs like DeepSeek-R1, Llama 4, and Phi-4 with BentoML and vLLM.
You can use this example as a foundation and customize it for your unique use cases.
-
Clone the repo and enter the Phi-4 folder:
git clone https://github.com/bentoml/BentoVLLM.git cd BentoVLLM/phi4-14b-reasoning -
Create a virtual environment and install dependencies:
python -m venv venv source venv/bin/activate # Recommend Python 3.11 pip install -r requirements.txt -
If you have a GPU with at least 80GB VRAM (e.g., NVIDIA A100 80G), you can start the server locally:
bentoml serve
Your model will now be accessible at http://localhost:3000/, with all the API specifications automatically generated.
If your local machine lacks sufficient resources, skip ahead to the next section.
Deploy Phi-4-reasoning to BentoCloud#
BentoCloud is a unified AI inference platform for building and scaling AI systems without managing infrastructure. You can run any model in BentoCloud’s managed compute resources, or Bring Your Own Cloud and deploy inside your private AWS, GCP, or Azure account, NeoCloud and on-premises environments.
To get started:
-
Sign up for BentoCloud and log in.
bentoml cloud login -
Deploy the model and optionally set a name.
bentoml deploy -n <your_deployment_name> -
Wait for the Deployment to be up and running. You can check the Deployment status like this:
import bentoml status = bentoml.deployment.get(name="<your_deployment_name>").get_status() print(status.to_dict()["status"]) # Example output: deploying -
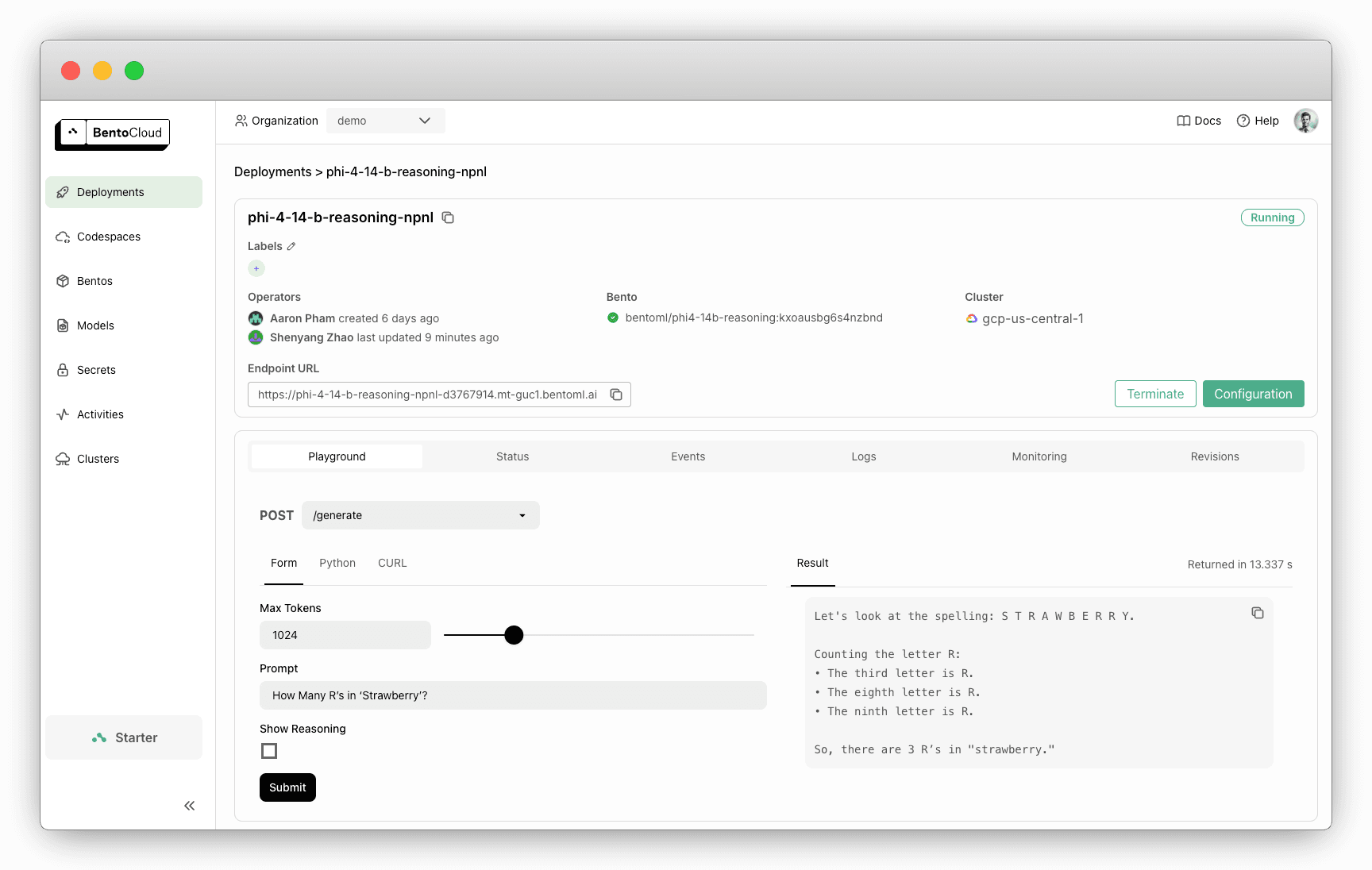
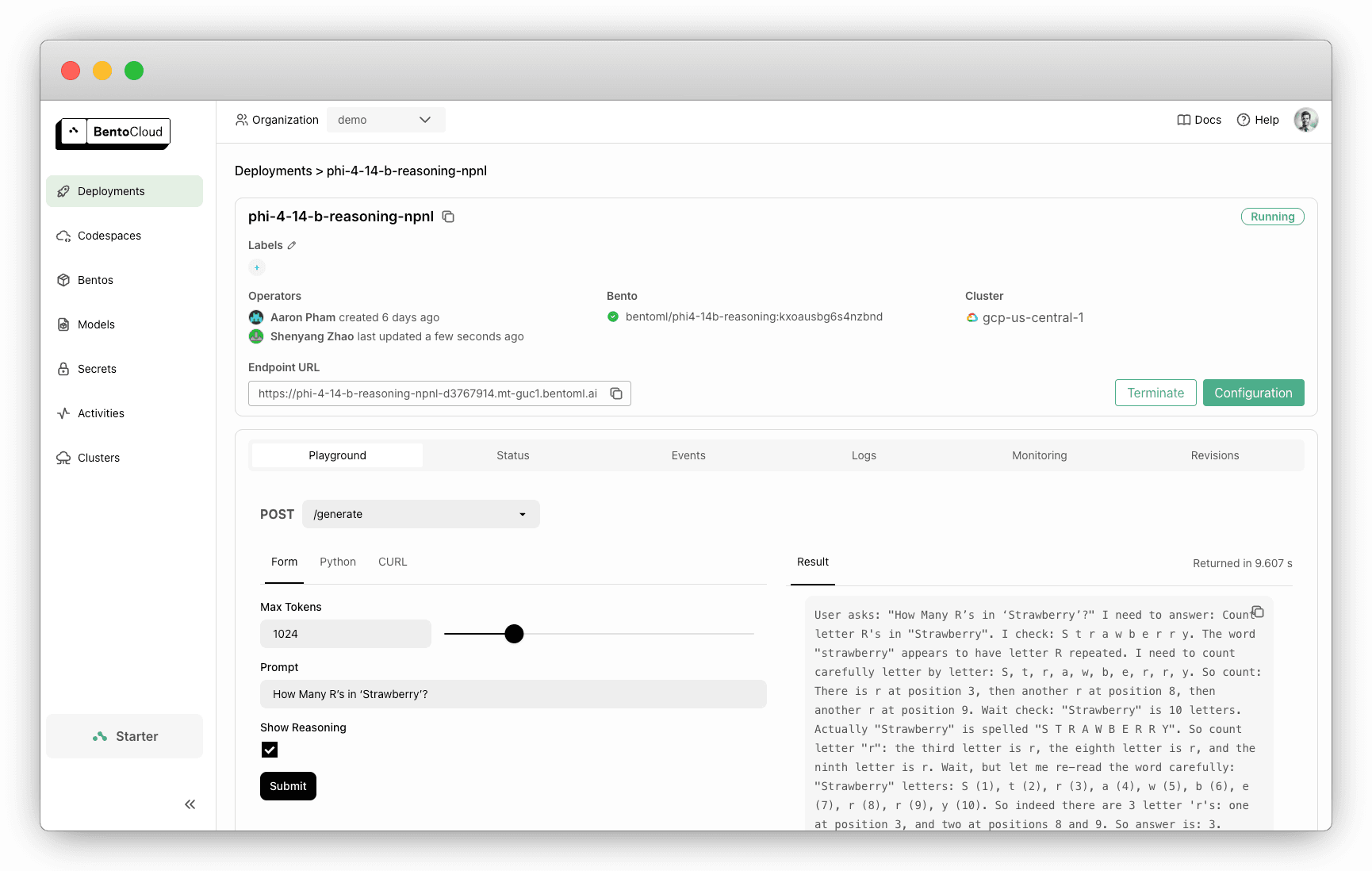
Once the Deployment is ready, interact with it on the BentoCloud console. Checking Show Reasoning will display the reasoning steps of the model.
Call the OpenAI-compatible API#
This project exposes an OpenAI-compatible API for easy integration.
-
Retrieve your Deployment endpoint first:
bentoml deployment get <your_deployment_url> -o json | jq ."endpoint_urls"[0] # Example: "https://phi-4-example-bento-d1234567.mt-guc1.bentoml.ai" -
Here's an example using the
openaiPython SDK. Make sure you replace the base URL.from openai import OpenAI client = OpenAI( base_url='https://phi-4-example-bento-d1234567.mt-guc1.bentoml.ai/v1', api_key='na' # set to your BentoCloud API token when endpoint protection is enabled ) # Use the following func to get the available models # model_list = client.models.list() # print(model_list) chat_completion = client.chat.completions.create( model="microsoft/Phi-4-reasoning", messages=[ { "role": "user", "content": "How many R's in 'Strawberry'?" } ], stream=True, ) for chunk in chat_completion: # Extract and print the content of the model's reply print(chunk.choices[0].delta.content or "", end="")
Scale the Deployment#
By default, your Deployment only has one replica. To scale it based on real-time traffic, run:
bentoml deployment update <your_deployment_name> --scaling-min 0 --scaling-max 5 # Set your desired count
You can also configure scaling on the Configurations page.
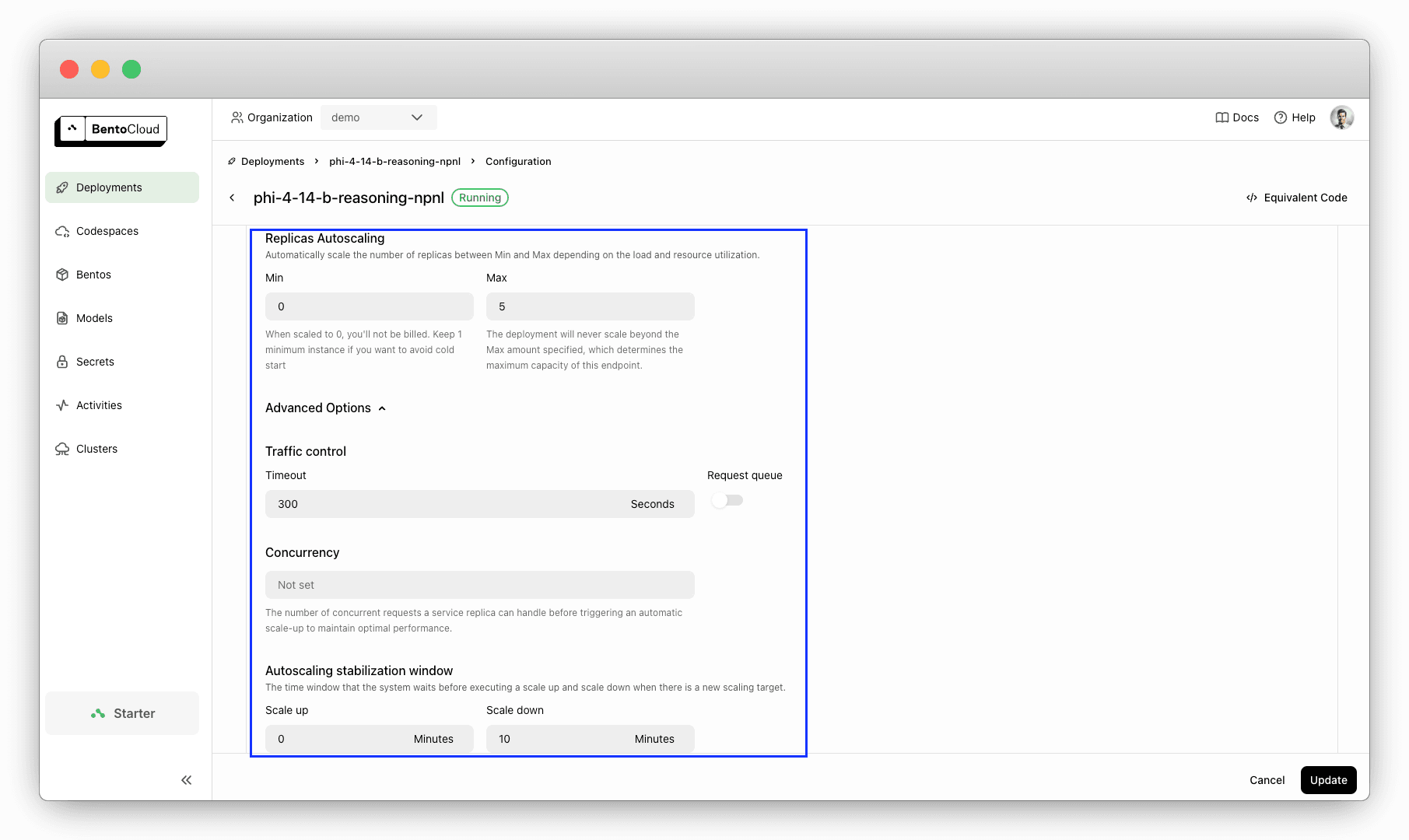
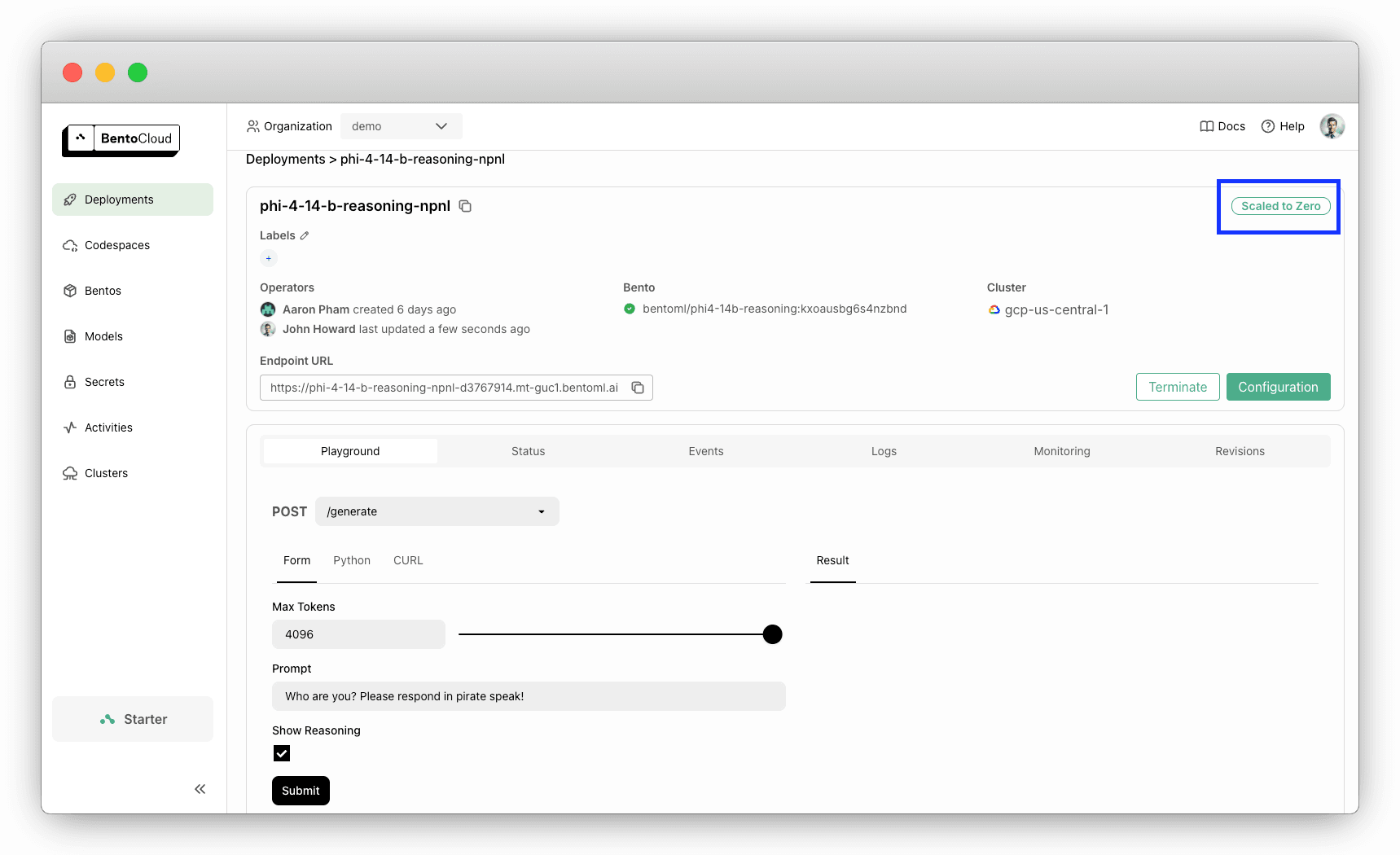
Setting the minimum count to 0 is useful for avoiding unnecessary costs during idle periods. The Deployment will automatically scale up when requests come in.
Update the Deployment#
One of the benefits of using BentoML is the ease of updating your Deployment. Want to improve the prompt formatting or update your inference logic? Simply modify your code locally (e.g., service.py), then push the update:
bentoml deployment update <your_deployment_name> --bento .
This redeploys your updated code to the same URL. No change is needed on the client side.
Monitor performance#
BentoCloud provides built-in observability dashboards to help you track usage and catch issues early.
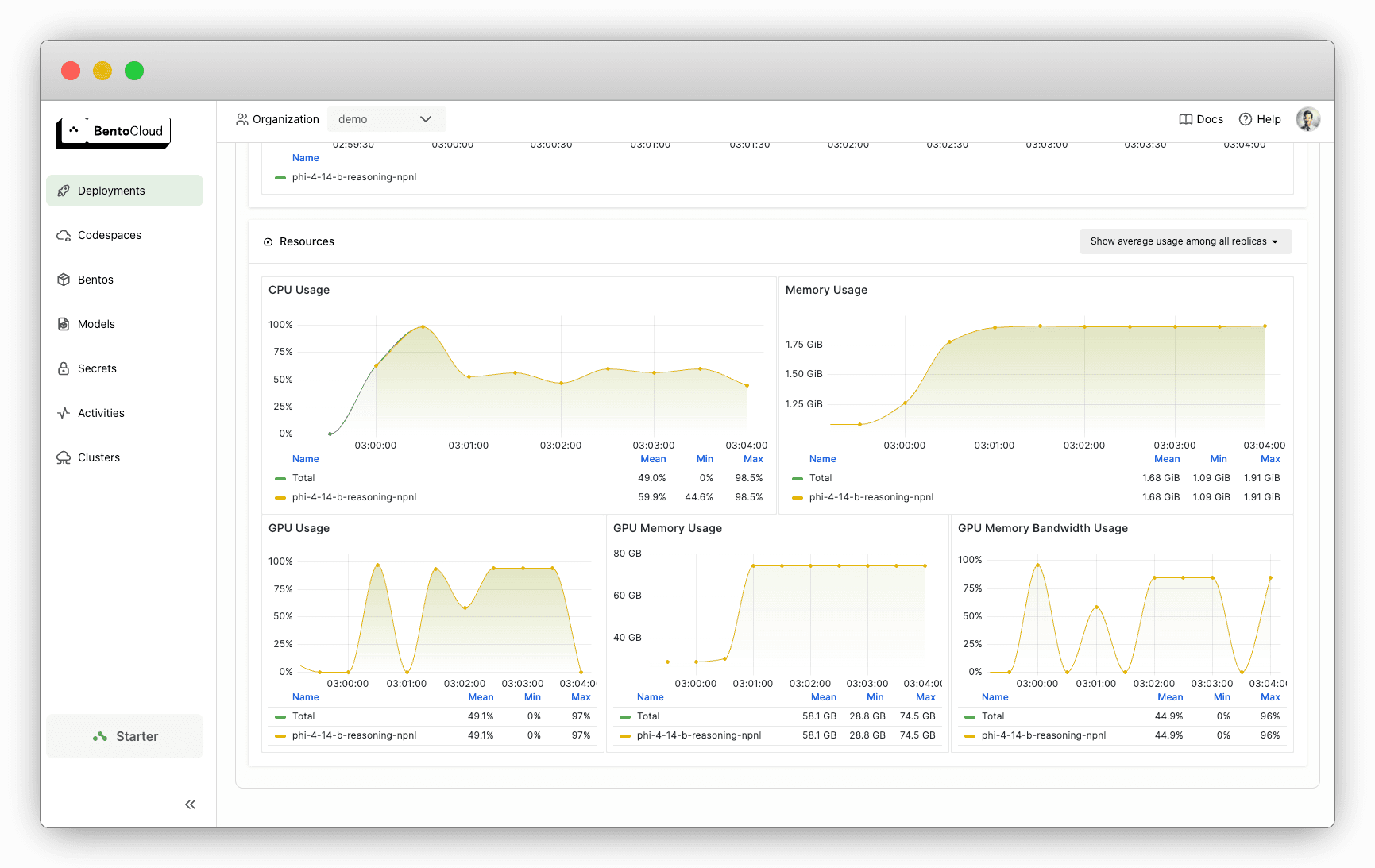
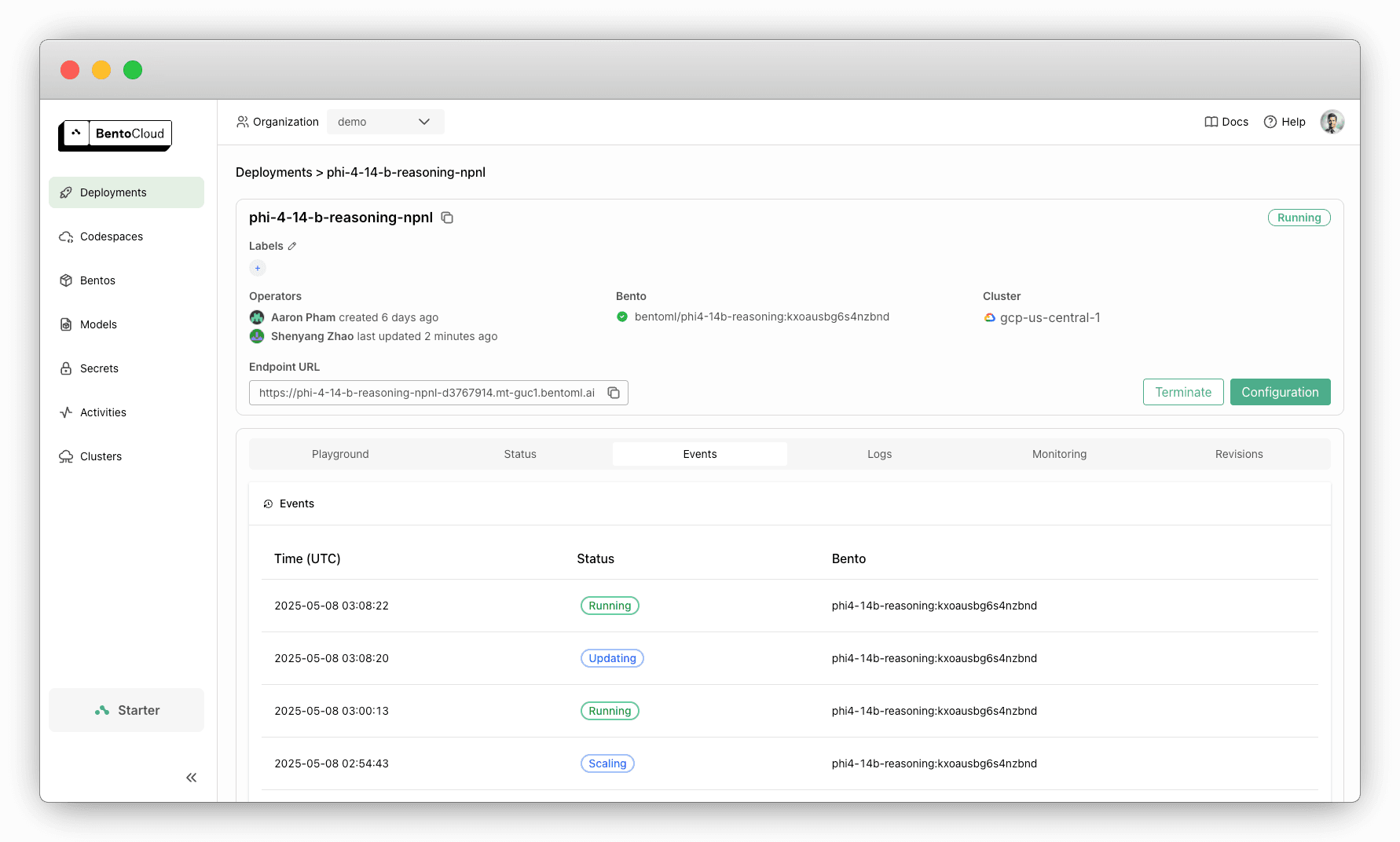
Conclusion#
Phi-4-reasoning demonstrates that smart training and fine-tuning strategies can allow small models to compete with giants. With BentoML, integrating this powerful model into your workflows is just a few steps away.
Get started today and say goodbye to infrastructure headaches around deployment, scaling, monitoring or maintenance.
- Read our LLM Inference Handbook
- Sign up for our inference platform to deploy your private inference API with Phi-4-reasoning.
- Join our developer community to get help, share projects, and stay up-to-date.
- Still have questions? Schedule a call with our experts.