BentoCloud: Fast and Customizable GenAI Inference in Your Cloud
Authors

Last Updated
Share

⚠️ Note: Bento is now part of Modular! Sign up for the Modular Platform and schedule a call with us to learn how Bento and Modular can help you serve high-performance inference in production.
The AI landscape has changed drastically over the past two years, driven by the rapid advancements in Large Language Models (LLMs) and Generative AI. Today, proprietary models from innovators like OpenAI and Anthropic offer cutting-edge capabilities easily accessible through a simple API call, enabling every organization to quickly build prototypes and reimagine what is possible with AI.
This convenience, however, comes with limited control and customization. For enterprise AI teams, especially in regulated industries where data sovereignty is crucial, sending sensitive data to an external API is often a deal breaker. Additionally, when building a business-critical AI application, relying solely on third-party systems limits the ability to differentiate your AI product and build competitive advantages by leveraging your proprietary data.
On the other hand, open-source AI is booming. Models like Llama, Mistral, Whisper, and Stable Diffusion offer promising alternatives. Organizations can customize these pre-trained models with their own datasets and optimize for specific business contexts. This is crucial for AI teams looking to build strong AI solutions that meet unique requirements and maintain a competitive edge.
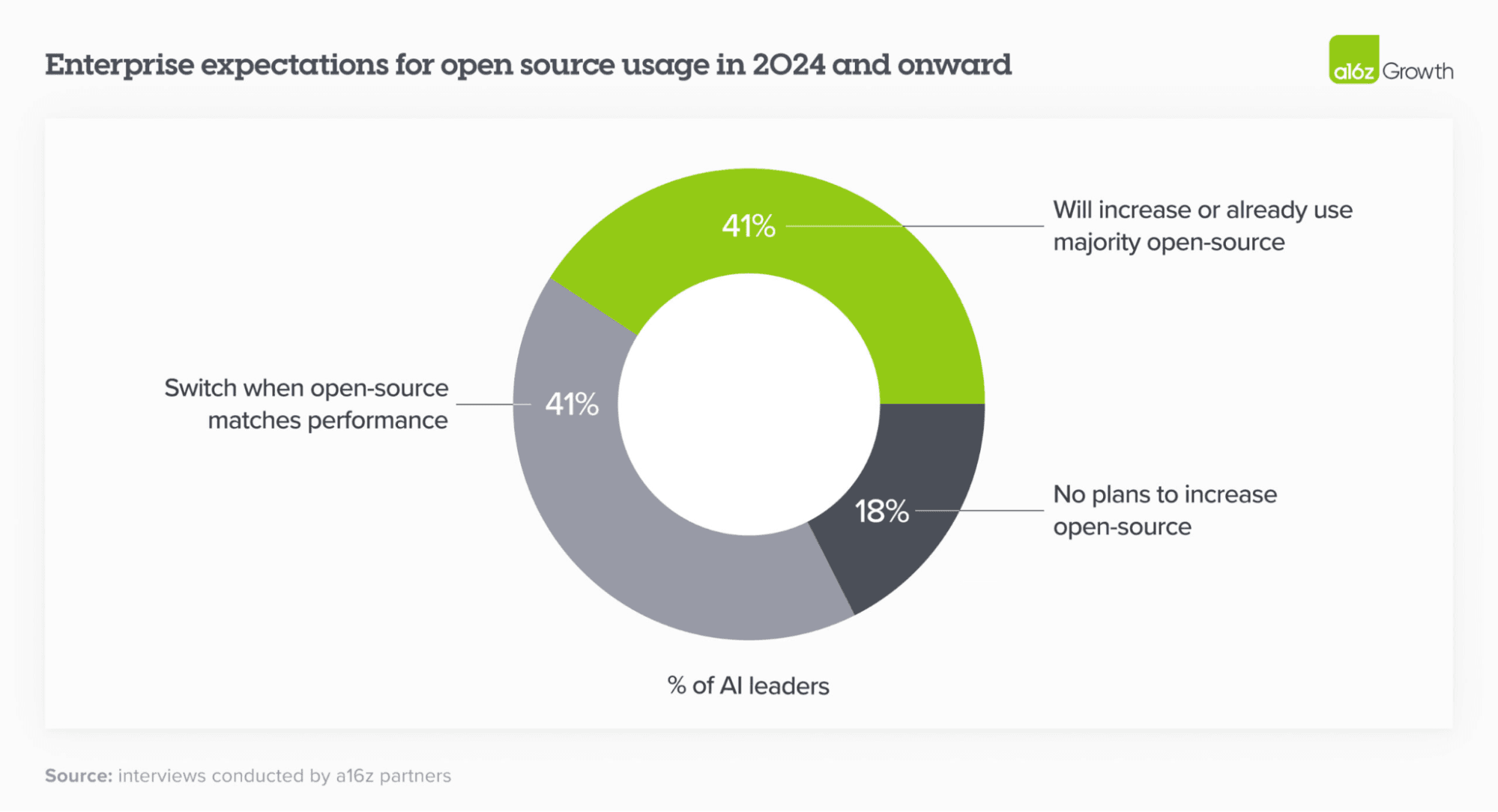
Yet, running large models reliably and efficiently in production remains a daunting challenge for most businesses. From optimizing model loading time, speeding up inference, and fast autoscaling, to multi-model serving, deployment automation, and observability - every step in the process requires specialized tooling and expertise. Building this in-house takes significant time and resources, often pulling focus from your core products and slowing innovation.
This critical gap is where BentoCloud comes in. BentoCloud is an inference platform for enterprise AI teams who need control, customization, and efficiency in their AI deployment. By addressing the core infrastructure challenges in AI inference, it allows your team to focus on what truly matters - leveraging AI to build a competitive edge and drive your business.
“BentoML has helped TomTom maintain focus on its core competency in maps and navigation services, while also trying out the latest AI technologies speedily” - Massimiliano Ungheretti, PhD, Staff Data Scientist at TomTom
Introducing BentoCloud#
We started BentoML in 2019 with a mission to streamline the path for machine learning teams to bring AI/ML models into production. Our open-source model-serving framework has since been adopted by thousands of AI teams, creating one of the largest AI developer communities focused on model serving and inference.
Built on this strong foundation, we created BentoCloud - an inference platform that takes the infrastructure complexity out of production AI workloads. BentoCloud brings cutting-edge inference and serving capabilities directly to your cloud environment, making it easy for AI teams to build fast, secure, and scalable AI applications.
Customizable AI Inference Tailored To You#
BentoCloud lets you deploy custom AI APIs with any open-source, fine-tuned, or custom models. You can choose the right model for the task, easily configure scaling behaviors, and leverage inference optimizations. This flexibility lets you decide how to balance cost/latency trade-offs, giving you a faster response time and lower inference cost.
Delightful Developer Experience#
We’ve simplified the entire model deployment workflow with a focus on developer experience. Our rich open-source ecosystem lowers the learning curve and integrates seamlessly with your existing systems. This helps accelerate development iteration cycles, production operations, and CI/CD processes, promote standardization across teams, and empower AI teams to ship models to market faster with greater confidence.
State-of-the-Art Inference Optimizations#
Powered by BentoML, the world’s leading open-source serving engine, BentoCloud simplifies AI model inference optimization. You can fully customize the inference setup to meet specific needs. We provide a suite of templates to help you jumpstart your AI project, leveraging the best-in-class inference optimizations while following common best practices. For example, you can explore our benchmarks on various LLM inference backends on BentoCloud, such as vLLM, MLC-LLM, LMDeploy, and TensorRT-LLM, to see how they perform.
Fast and Scalable Infrastructure#
BentoCloud offers advanced scaling capabilities like scaling-to-zero, optimized cold starts, concurrency-based auto-scaling, external queuing, and stream model loading. These features mean rapid scaling up in response to demand, improved resource utilization, and reduced inference costs.
We built BentoCloud with the goal of bringing the best infrastructure for efficient and scalable inference to every enterprise AI team, empowering developers to easily go from local prototypes to production-grade deployments, and optimize performance across a diverse set of inference workloads.
Why Control and Customization Matter for Enterprise AI#
In today's rapidly evolving AI landscape, enterprise AI teams demand more than just access to powerful models - they require the ability to shape and fine-tune AI solutions to their specific needs, and scale AI operations in a secure way. Unlike other vendors offering AI capabilities via an API, BentoCloud is designed to address these key challenges by giving our customers full control over how and where models are deployed, as well as the flexible customization, necessary for building their unique competitive edge:
1. Bring Your Own Cloud#
BentoCloud’s Bring-Your-Own-Cloud (BYOC) option takes our entire serving and inference stack to your own cloud infrastructure, making it easier than ever to create private and secure model deployment and ensuring that your model and sensitive data never leave your virtual private cloud (VPC). You benefit from a fully managed infrastructure optimized for performance and cost, while meeting enterprise-grade data security needs, without the burden of building and maintaining it in-house.
2. The Multi-Cloud Future#
The cost and availability of GPU compute resources can fluctuate across different clouds. BentoCloud abstracts away the differences between cloud vendors, enabling developers to deploy the same inference setup across clouds, including AWS, Azure, and GCP, with upcoming support for Oracle Cloud, CoreWeave, and Lambda Labs. This flexibility allows organizations to minimize risks and secure competitive pricing as they scale their AI workloads.
3. Predictable Behavior and Latency#
Unlike calling an API from a black box, BentoCloud lets developers create dedicated AI deployments with full control over model inference configuration. This gives you guaranteed speed and reliability, allowing you to manage latency and promise SLAs for critical applications, or optimize costs for less time-sensitive workloads.
4. Your Model, Your Data#
AI models are only as good as the data they're trained on. It’s proven that smaller, fine-tuned LLMs can surpass the capabilities of larger, generic models, at a much lower inference cost. Customized models, leveraging your unique proprietary data and efficient fine-tuning methods, unlocks your distinct competitive advantages in your market. With BentoCloud, you can quickly deploy your custom models as efficient and scalable inference APIs that are ready for production.
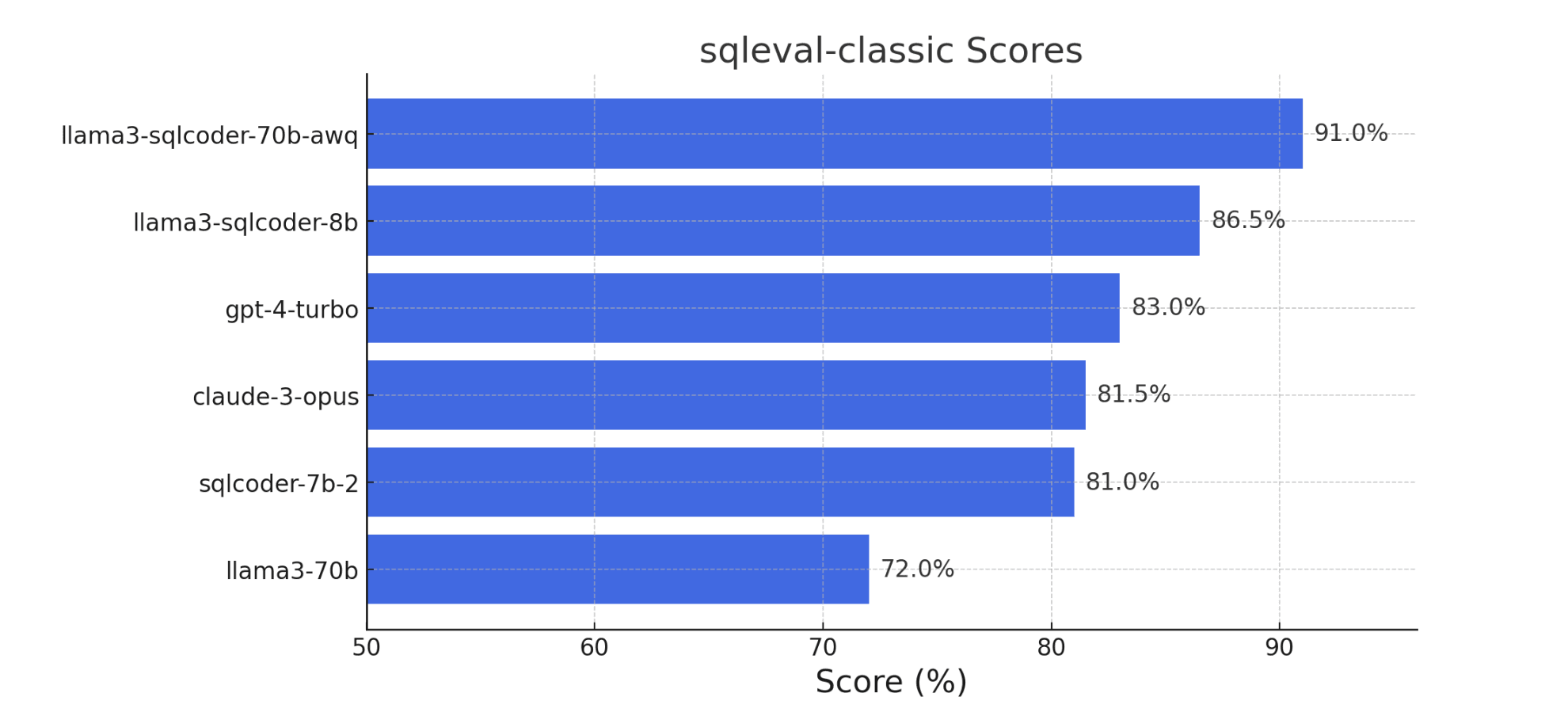
Open source models fine-tuned from Llama3-8B beat gpt-4-turbo and claude-3 in Text-to-SQL generation (Image source).
5. Shift Towards Small Task-Specific Models#
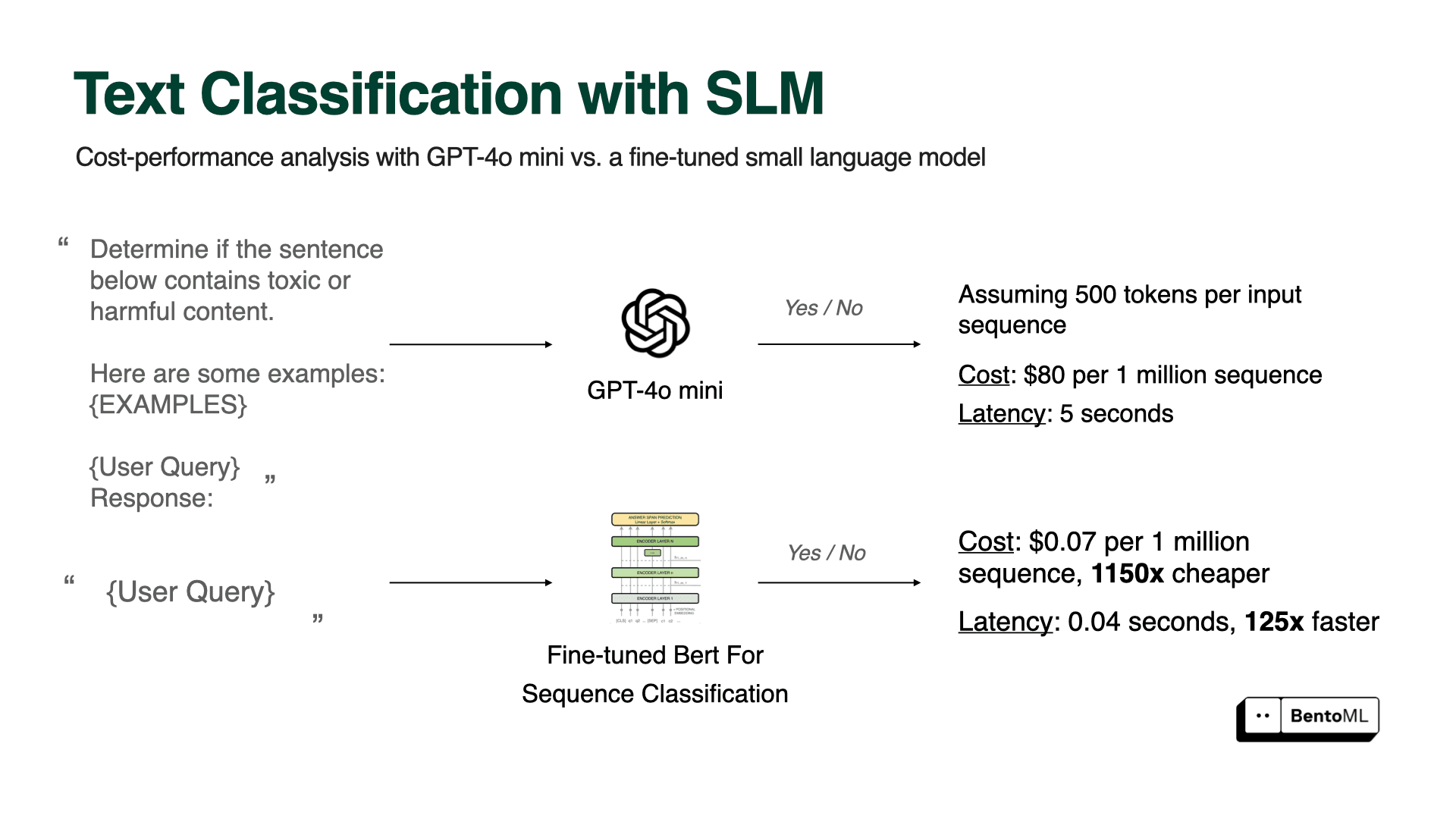
Most enterprises are moving towards using multiple models, each with varying performance goals, quality, and cost, specialized for a single task. For instance, you don't need a 175B parameters LLM to perform simple sentiment analysis or text classification tasks. By choosing the right model for each task, you can achieve better performance at a lower cost. Smaller models also mean you won’t always need the most advanced GPUs, freeing you from being blocked by the GPU shortage or their expensive price tag.
6. Compound AI systems#
As many AI developers begin to realize, “State-of-the-art AI results are increasingly obtained by compound systems with multiple components, not just monolithic models”. At BentoML, we’ve been building towards this vision from day one. Developers can easily incorporate business logic, compose multiple models, and mix various serving patterns to create production-ready compound AI systems, such as RAG, Multi-LLM routing or Agentic workflows.
In summary, by embracing control and customization, BentoCloud helps future-proof your AI initiatives and align them with your long-term AI strategy. Control frees you from lock-in to any single model provider or cloud service provider, keeping your data and models within secured environments; customization allows you to tailor your AI serving systems to your unique use cases, data, and business requirements.
The Road Ahead: Future-Proof Your AI Initiative Today#
At BentoML, our mission is to empower every organization to win and compete with AI. While many AI use cases are still powered by proprietary models today, we believe in the shift towards specialized models that leverage proprietary data, especially for business-critical AI applications. By providing the inference platform that you can control and customize, we help you accelerate time-to-market while aligning with your security and strategic needs.
As an open-source community, BentoML is constantly evolving, ensuring you stay updated with the latest advancements in AI infrastructure. Join our community today, to become part of this movement.