Building A Production-Ready LangChain Application with BentoML and OpenLLM
Authors

Last Updated
Share

LangChain is an open-source framework for creating applications powered by large language models (LLMs), like AI chatbots and personal assistants. When it comes to LLMs, you can also use OpenLLM, an open-source platform in the BentoML ecosystem designed specifically for serving and deploying LLMs in production. As OpenLLM provides seamless support for both LangChain and BentoML, you can harness their combined strengths, unlocking enhanced capabilities from each platform.
In this blog post, I will build a LangChain application capable of creating self-introductions for job interviews. Our journey begins with a simple script, eventually evolving it into a sophisticated version that exposes an API endpoint, allowing for wider external interactions.
Before you begin#
- Install LangChain and OpenLLM by running
pip install langchain openllm. BentoML is automatically installed with OpenLLM. - databricks/dolly-v2-7b and databricks/dolly-v2-12b are the two models used in this blog post. I used an AWS EC2 instance of type
g4dn.12xlargeto avoid potential resource limitations. The resource requirements vary with the model; you can gauge the necessary vRAM using the Model Memory Calculator from Hugging Face.
v1: Creating the initial LangChain application#
LangChain’s integration with OpenLLM is straightforward. Instantiate an llm object using OpenLLM from langchain.llms by specifying the required model details:
from langchain.llms import OpenLLM llm = OpenLLM(model_name="dolly-v2", model_id='databricks/dolly-v2-7b') res = llm("Create a self introduction for me.") print(res)
Note: The databricks/dolly-v2-7b model powers this application. You can run openllm models to see all supported models. Running the script triggers OpenLLM to download the model to the BentoML local Model Store if it’s not already available.
Run this script and here is the result returned:
"Hi, my name is Joe, and I am here to help you. As a data analyst, my job is to make sense of data and derive business value from it. I am experienced in a wide variety of data roles and types and can help you find your way with my eyes wide open. I offer a free 30 minute consultation to discuss your data needs."
The self-introduction is ok, but ideally the application should solicit user-specific details like their name, industry, educational background, and skill set, for a more tailored experience. Moreover, you may want to provide the model with additional contextual information to refine the self-introduction for specific scenarios, like a job interview.
v2: Improving the application with template prompts#
LangChain’s prompt templates offer the flexibility of integrating scenario information and customized variables. These templates are essentially pre-defined recipes, such as instructions and few-shot examples, which guide the LLMs to generate content for specific tasks. As shown below, I embedded a template to generate self-introductions for software engineer job interviews:
from langchain.prompts import PromptTemplate prompt = PromptTemplate( input_variables=["name", "industry", "work_years", "education", "skills"], template=""" You are a self-introduction creator with a strong background in interviewing and persuasive writing. The content you create lets the interviewer grasp the candidate's unique value proposition swiftly, aligning it with the job's requirements and the company's ethos. You are given the following information to craft a compelling self-introduction for a software engineer role. Name: {name} Industry: {industry} Experience: {work_years} Education: {education} Skills: {skills} Self introduction: """, )
With a ready-to-use template, you can create an LLMChain, a common object in LangChain that adds functionality around the language model, and specify the required variables to generate dynamic self-introductions. Here is the entire application v2 code for your reference. Note that this time I used databricks/dolly-v2-12b as the model for better inference performance.
from langchain.chains import LLMChain from langchain.llms import OpenLLM from langchain.prompts import PromptTemplate llm = OpenLLM(model_name="dolly-v2", model_id="databricks/dolly-v2-12b", device_map="auto") # Define the PromptTemplate using the given template prompt = PromptTemplate( input_variables=["name", "industry", "work_years", "education", "skills"], template=""" You are a self-introduction creator with a strong background in interviewing and persuasive writing. The content you create lets the interviewer grasp the candidate's unique value proposition swiftly, aligning it with the job's requirements and the company's ethos. You are given the following information to craft a compelling self-introduction for a software engineer role. Name: {name} Industry: {industry} Experience: {work_years} Education: {education} Skills: {skills} Self introduction: """, ) # Initialize the LLMChain with the provided llm and prompt chain = LLMChain(llm=llm, prompt=prompt) # Define the variables name = "John Smith" industry = "AI" work_years = "5 years" education = "MSc, Computer Science, Stanford University" skills = ["Kubernetes", "BentoML", "AWS", "Python", "Go", "Java"] # Run the LLMChain with the defined variables res = chain.run( {"name": name, "industry": industry, "work_years": work_years, "education": education, "skills": ", ".join(skills)} ) print(res)
Run this application and here are two example results for your reference.
Example output 1:
"Hi, I'm John Smith. I'm a software engineer based in the San Francisco Bay area with over 5 years of experience working in the artificial intelligence industry. My past jobs have involved building data pipelines and distributed machine learning workflows, with a focus on Kubernetes and AWS. I also teach Python and Go to people with no background in coding. Beyond work, I am an avid cyclist and microservices fan. I'm very happy to be considered for this role, and look forward to discussing my experience and skills further with you."
Example output 2:
"I am an experienced software engineer with extensive experience in Kubernetes, BentoML and AWS. In my current role, I use my extensive experience to help our engineering team deploy our products to AWS, as well as contribute to BentoML pipelines to improve our product development and delivery process. Before taking on this role, I studied computer science at Stanford University and developed ML-based sentiment analysis tools in my final year project. I am now excited to apply my skills in this field to help develop and improve our engineering culture."
As you can see, this enhanced version is able to generate more personalized and contextually relevant introductions.
v3: Integrating the application with BentoML#
OpenLLM provides first-class support for BentoML. Integrating the application with BentoML allows you to leverage the benefits of the BentoML framework and its ecosystem. For example, you can wrap the llm instance created previously in a BentoML Runner for better scaling and inference; you are also able to expose an API endpoint (available on a Swagger UI) for the BentoML Service containing the Runner for external interactions with users.
For input validation and structure, I used pydantic to ensure the correctness of user-provided data. Furthermore, it may be a good idea to provide sample inputs, which are pre-populated on the Swagger UI for clarity. See the following code snippet for details.
from pydantic import BaseModel # Define a Pydantic model for input validation class Query(BaseModel): name: str industry: str work_years: str education: str skills: t.List[str] llm_config: t.Dict[str, t.Any] # Sample input for the Service SAMPLE_INPUT = Query( name="John Smith", industry="AI", work_years="5 years", education="MSc, Computer Science, Stanford University", skills=["Kubernetes", "BentoML", "AWS", "Python", "Go", "Java"], llm_config=llm.runner.config.model_dump(), )
I list the entire application v3 code below, usually stored in a service.py file in BentoML.
from __future__ import annotations import typing as t from langchain.chains import LLMChain from langchain.llms import OpenLLM from langchain.prompts import PromptTemplate from pydantic import BaseModel import bentoml from bentoml.io import JSON, Text prompt = PromptTemplate( input_variables=["name", "industry", "work_years", "education", "skills"], template=""" You are a self-introduction creator with a strong background in interviewing and persuasive writing. The content you create lets the interviewer grasp the candidate's unique value proposition swiftly, aligning it with the job's requirements and the company's ethos. You are given the following information to craft a compelling self-introduction for a software engineer role. Name: {name} Industry: {industry} Experience: {work_years} Education: {education} Skills: {skills} Self introduction: """, ) # Function to generate an OpenLLM instance def gen_llm(model_name: str, model_id: str | None = None) -> OpenLLM: lc_llm = OpenLLM(model_name=model_name, model_id=model_id, embedded=False) # Download the model for the LLM instance lc_llm.runner.download_model() return lc_llm llm = gen_llm("dolly-v2", model_id="databricks/dolly-v2-12b") chain = LLMChain(llm=llm, prompt=prompt) # Define a BentoML Service with the LLM Runner svc = bentoml.Service("self-introduction-service", runners=[llm.runner]) class Query(BaseModel): name: str industry: str work_years: str education: str skills: t.List[str] llm_config: t.Dict[str, t.Any] SAMPLE_INPUT = Query( name="John Smith", industry="AI", work_years="5 years", education="MSc, Computer Science, Stanford University", skills=["Kubernetes", "BentoML", "AWS", "Python", "Go", "Java"], llm_config=llm.runner.config.model_dump(), ) # Define the API for the Service with JSON as input and plain text as output @svc.api(input=JSON.from_sample(sample=SAMPLE_INPUT), output=Text()) def generate(query: Query): return chain.run( {"name": query.name, "industry": query.industry, "work_years": query.work_years, "education": query.education, "skills": ", ".join(query.skills)} )
Start the application server using:
bentoml serve service:svc --reload
Access the application server at http://0.0.0.0:3000. In the Swagger UI, scroll down to the /generate endpoint, and click Try it out. Let’s try something different this time by changing the industry, education, and skills fields, and click Execute.
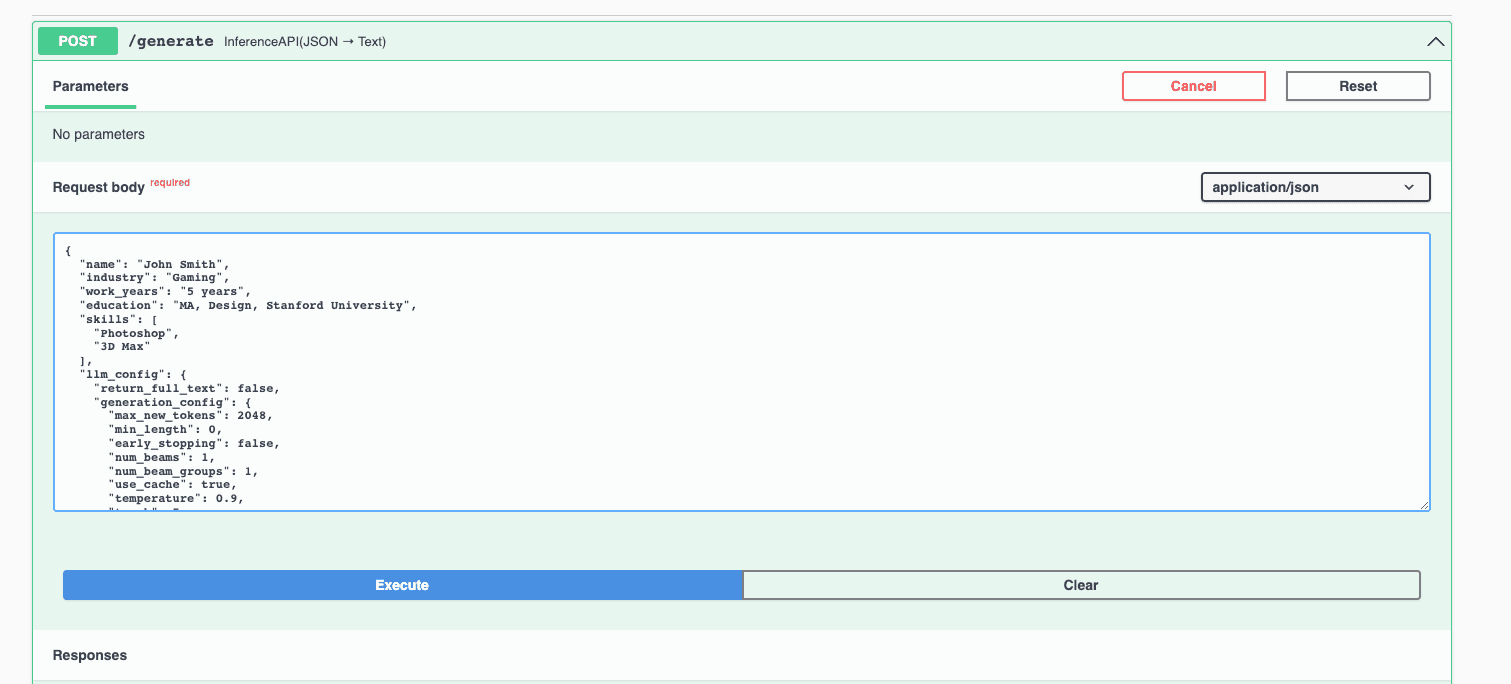
Example output (obviously there are some hallucinations 🤣):
"Hello, I am John Smith. After graduating from Stanford University, I have been working as a software engineer for 5 years. Throughout my career, I have used my skills in 3D graphics and computer vision to contribute taxpayers in the gaming industry. My work in this space has involved calibrating camera parameters and creating 3D assets for game characters and environments. My job has required me to use my extensive knowledge of 3D graphics and computer vision to help create realistic visuals. Additionally, I recently launched a camera calibration tool that has been adopted by other engineers in the industry. I feel very fortunate to be working in such a creative industry. I hope to provide value to your team in some way in the future."
You can then build the LangChain application into a Bento, the standardized distribution format in BentoML, and ship it to BentoCloud for production deployment. Alternatively, containerize the Bento and deploy the resulting Docker image anywhere.
Conclusion#
Since the open-source release of OpenLLM, we have noticed growing attention and enthusiasm around the project. One of the highlighted features is its integration with popular frameworks to create AI applications. While I delved into its synergy with BentoML and LangChain in this post, OpenLLM also supports Transformers Agents. Stay tuned for a future blog post where I will unpack this integration in greater detail. As always, happy coding! ⌨️
More on BentoML and OpenLLM#
To learn more about BentoML, OpenLLM, and other ecosystem tools, check out the following resources:
- [Doc] OpenLLM integration with LangChain
- [Doc] Deploy a large language model with OpenLLM and BentoML
- [Blog] Deploying Llama 2 7B on BentoCloud
- [Blog] Deploying Stable Diffusion XL on BentoCloud and Dynamically Loading LoRA Adapters
- Don’t miss out on the chance to be an early adopter! BentoCloud is still open for early sign-ups. Experience a serverless platform tailored to simplify the building and management of your AI applications, ensuring both ease of use and scalability.