What is GPU Memory and Why it Matters for LLM Inference
Authors

Last Updated
Share

You load a 70B LLM on 2× NVIDIA A100 80 GB GPUs and think:
“This has more memory than I need. My model should run fine.”
The model loads successfully. But the moment you start generating text, VRAM usage spikes. Suddenly, you hit the Out of Memory (OOM) error.
Your batch size collapses to 1. Your context length has to be cut in half. Your inference throughput drops to a crawl.
So you start searching for fixes like KV-aware routing and cache offloading. Every solution sounds promising, but brings new dependencies, complex optimization tricks, and performance trade-offs. Before you know it, you’re buried in GitHub issues and CUDA error logs. This is all because your GPU memory didn’t behave the way the spec sheet said it would.
It doesn't have to be this hard.
In this post, we’ll clear up the confusion. You’ll learn:
- What GPU memory is
- How LLMs use GPU memory during inference
- How to calculate memory requirements
- How to optimize memory usage and how our Inference Platform can help you
What is GPU memory (VRAM)?#
When people talk about GPU memory (e.g., A100 80 GB) for inference, they often mean dedicated VRAM (video random access memory). It is high-speed memory physically attached to the GPU chip, such as HBM3 or GDDR6X.
Key facts:
- Extremely high speed. Modern data center GPUs can read and write data at terabytes per second. For example, an NVIDIA H200 reaches up to 4.8 TB/s of memory bandwidth.
- Exclusive to the GPU. VRAM isn’t shared with the CPU. It’s a dedicated workspace.
- Stores what the model needs at runtime. That mainly includes model weights, activations, and KV cache.
- Directly impacts LLM inference performance. VRAM capacity and bandwidth influence throughput, latency, maximum context length, and how many concurrent requests you can serve.
Note that strictly speaking, GPU memory and VRAM are not exactly the same thing.
GPU memory is a broader term that means whatever memory the GPU is currently using. It usually means VRAM (and people often use the terms interchangeably), but can refer to other sources depending on the system architecture.
For example, integrated GPUs are the most common case where GPU memory ≠ VRAM. They carve out a portion of system RAM, and there's no dedicated VRAM hardware at all. We’ll break that down in the next section.
What is shared GPU memory?#
Shared GPU memory refers to system RAM that the GPU can use when it runs out of its own dedicated VRAM.
- It’s not physically located on the GPU chip.
- It’s part of the CPU’s memory (DRAM) that’s dynamically allocated to the GPU when needed.
- It’s common in integrated GPUs (like Intel Iris, Apple M-series, or AMD APUs), where GPU and CPU share the same physical memory pool.
If you’re using data center GPUs like A100 or H200 for LLM inference, you don’t need to care about shared GPU memory. They rely entirely on their own dedicated HBM, which is fast and optimized for large-scale AI workloads.
Note that the term “shared GPU memory” discussed here is not the same as shared memory (SMEM) used in GPU programming, which is a fast, on-chip memory inside each GPU core (SM) for cooperation between threads. If you’re interested in how on-chip memory (registers, shared memory, caches) impacts performance in LLM inference, see the LLM Inference Handbook for a deeper explanation.
How GPU memory is used in LLM inference?#
GPU memory isn’t just a container for model weights. It’s actively consumed throughout the entire inference process. At a high level, VRAM is used for:
- Loading model weights
- Building and expanding the KV cache during prefill and decode
- CUDA, framework and runtime overhead
Let’s break down each stage.
Model weights#
Before inference starts, all model weights must be loaded into GPU memory (or sharded across GPUs if using tensor parallelism).
You can calculate the baseline memory required just to load the model like this:
Model Memory ≈ num_parameters × bytes_per_parameter
For example, a 70B model in FP16 precision requires:
70B × 2 = 140 GB
Note: FP32 → 4 bytes, FP16/BF16 → 2 bytes, INT8/FP8 → 1 byte, INT4/FP4 → 0.5 bytes
This is why a single A100 80 GB cannot hold a 70B FP16 model without quantization or multi-GPU sharding.
KV cache#
Once inference begins, memory consumption continues to grow due to the KV cache.
During prefill, the model processes the full input prompt.
- It builds a KV cache to store the key and value vectors for every token at every layer
- The KV cache grows linearly with the input sequence length.
- Memory usage can increase rapidly for long prompts.
During decoding, the model generates tokens one by one autoregressively. Each new token appends to the KV cache. Even if the prompt was short, long generations would still expand the KV cache significantly. Learn more about LLM inference in our handbook.
For chat applications with multi-turn conversations, every new turn must include all previous messages. This means:
- The effective context window grows with each turn
- The KV cache becomes the dominant VRAM consumer
- Eventually, memory fills up even if the model weights fit comfortably
This is why models with long context windows require GPUs with large VRAM.
Framework + CUDA overhead#
Even after accounting for weights and KV cache, a few more items consume VRAM:
- CUDA kernels and workspaces
- Framework-specific allocators (e.g., PyTorch fragmentation)
- Runtime overhead from vLLM, TensorRT-LLM, or SGLang
- Temporary activation memory during prefill
The specific overhead size depends on the framework and GPU.
How to calculate the required GPU memory for an LLM#
A rough estimate for the required GPU memory can be calculated by multiplying the number of parameters by the bytes per parameter and then add extra overhead (%).
Memory (GB) = num_parameters × bytes_per_parameter × (1 + Overhead)
For LLM inference, the real variable you must watch is the KV cache, not the model weights. This is what grows with context length, batch size, and multi-turn interactions.
How to calculate the KV cache size#
The KV cache stores the key/value vectors for every token the model has processed. Its size grows linearly with sequence length, batch size, and number of layers.
A simplified formula:
KV Cache Size (GB) = 2 × batch_size × seq_len × num_layers × hidden_dim × bytes_per_parameter / 1024³
You can experiment with different batch sizes or context windows using the interactive KV cache calculator online.
Why an LLM “fits on paper” but still runs out of VRAM#
Before LLMs became common, AI teams were used to serving small NLP or vision models. They were only a few hundred MBs to a few GBs, so a single GPU could easily host multiple models at once with techniques like MIG (Multi-Instance GPU).
But note that in such cases each model requires very little memory and compute usage is low.
This led to the expectation that “If my LLM is 60 GB, an 80 GB GPU should be enough and I might be able to run another small model on the same GPU.”
However, LLMs behave very differently. They don’t just load weights; they grow at runtime.
As mentioned in previous sections, even if an LLM’s weights fit comfortably in VRAM, it still needs a large and growing amount of memory for the KV cache. It expands with every token in the prompt and every token generated during decoding.
This results in the problems people commonly hit:
- You can’t use large context windows. The KV cache scales linearly with sequence length. A model may load fine, but the moment you process a 4k, 8k, or 32k prompt, VRAM usage explodes.
- Concurrency stays low. If one request consumes a large amount of KV memory, you simply can’t serve many users at once.
- KV cache hit rate drops. Without enough room to store cache states, caches are evicted early and the model recomputes previous tokens repeatedly. As a result, your latency and inference cost will increase dramatically.
Ultimately, if you try inference, you’ll hit the classic OOM issue.
This is why an “LLM that needs 60 GB for weights” often cannot run reliably on an 80 GB GPU with long prompts, high concurrency, or multi-turn conversations.
The limiting factor isn’t the weights; it’s the runtime memory growth.
How to optimize GPU memory usage#
Once you understand why LLMs consume so much memory, the next question is: How do you reduce memory pressure and scale?
Below are the some of the most effective strategies used in production. All of them work, but several require complex engineering to deploy correctly.
And that’s exactly why we built our inference platform: to give AI teams all of these optimizations out-of-the-box, without hiring a dedicated infra team.
Quantization#
Quantization reduces the precision of model weights (e.g., from FP16 to INT8 or INT4), which lowers memory usage.
For example, a 70B model in FP16 requires 140 GB for model weights alone, plus additional memory for KV cache and overhead. After INT4 quantization, the weights need 35 GB of VRAM. This is a 4× reduction in memory footprint, enough to run a previously multi-GPU model on a single H200 (141 GB) with room left for KV cache and other overhead.
Note that quantization does introduce accuracy degradation. However, modern quantization methods like GPTQ and AWQ minimize this loss. For many workloads (chatbots, RAG, internal tools), the gains in memory savings and throughput outweigh the precision trade-off.
How Bento helps:
Bento supports any open-source, fine-tuned, or custom model, including quantized formats (INT8, FP8, INT4, GGUF, AWQ, GPTQ, etc.). You can load and serve quantized models directly without extra engineering work, container hacks, or custom inference wrappers.
Distributed inference techniques#
Distributed inference lets you spread the workload across multiple GPUs when a model or context window exceeds the capacity of a single device.
Tensor parallelism#
Tensor parallelism splits the internal computations of each layer across multiple GPUs. Instead of placing entire layers on different devices, it slices the layer's tensors into smaller chunks and distributes them across multiple GPUs.
This is useful when:
- the model is too large to fit on a single GPU, or
- long-context workloads cause memory usage to exceed a single device’s capacity
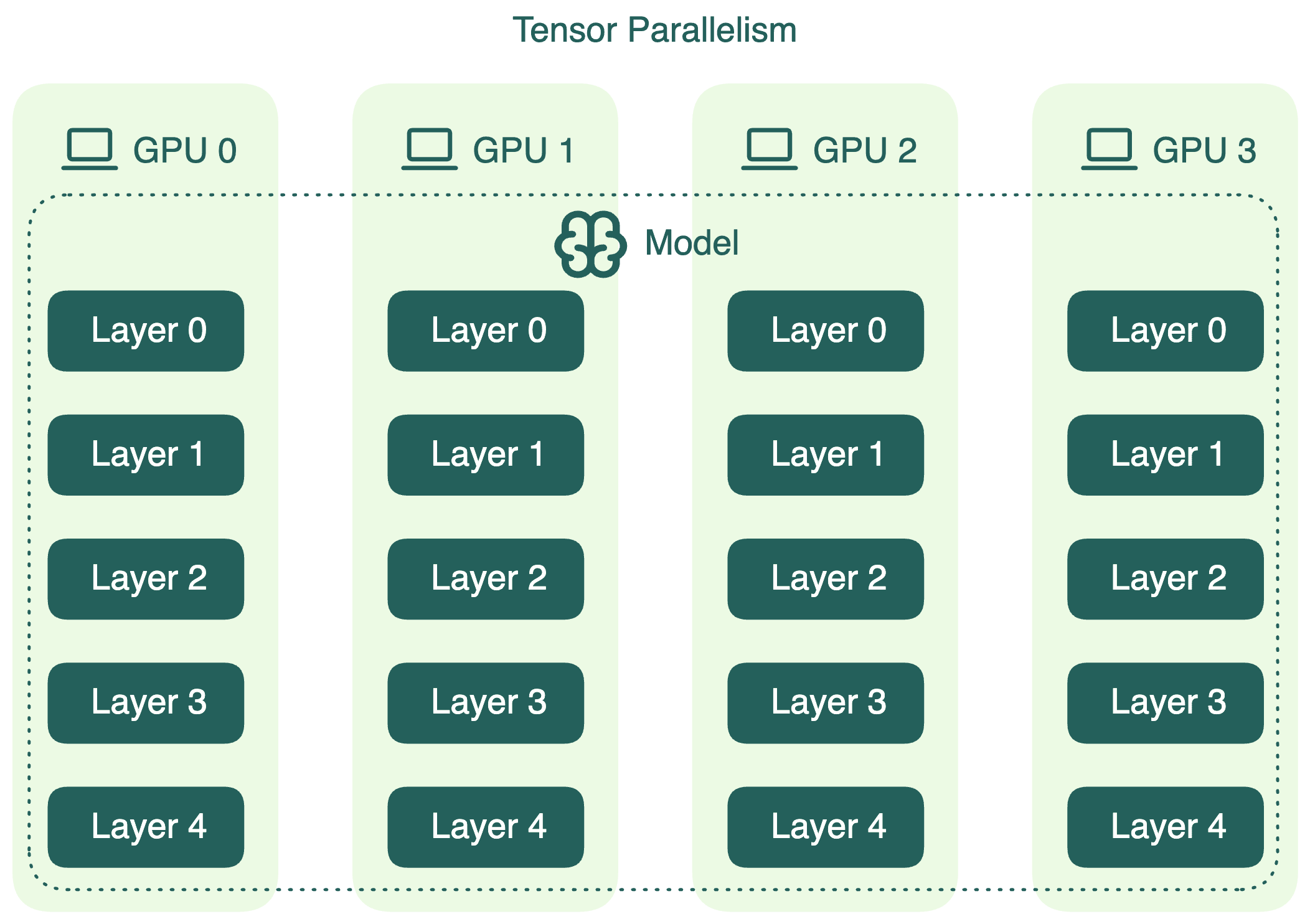
However, tensor parallelism introduces significant communication overhead, which:
- increases latency
- demands high-bandwidth interconnects
- adds complexity to your deployment setup
The overhead can become a bottleneck and affect LLM performance if not carefully optimized.
KV cache optimizations#
KV cache is often the real memory bottleneck. You can integrate multiple runtime strategies to control its growth and reduce VRAM usage.
-
Prefix caching: Reuses shared prompts across requests and users (e.g., system prompts). This cuts redundant KV computation and is especially useful for chat applications, RAG systems, and AI agents.
-
KV-aware routing: Ensures tokens for the same request are executed on the same GPU or worker, preventing fragmented KV allocations and improving the cache hit rate. In our internal tests with long context data (>20K), KV-aware routing delivered:
- 12× higher input throughput
- 3.5× higher output throughput
- 4× lower TTFT
- 90%+ prefix cache hit rates
-
KV cache offloading: Moves less frequently used KV blocks to lower-cost storage like CPU memory or disk, freeing up VRAM without blocking token generation.
These strategies work, but they are hard to implement yourself. To configure all of them manually, you’d need to handle:
- multi-GPU communication and synchronization
- Custom CUDA kernels or inference backends
- routing logic across workers to maximize cache reuse
- KV cache eviction and offloading logic
Most AI teams don’t have the engineering bandwidth to build and maintain this infrastructure.
How Bento helps:
Bento packages these optimizations into a production-ready inference platform so you don’t have to reinvent the entire inference stack:
- Automatic distributed inference with frameworks like MAX, vLLM, and SGLang
- Built-in KV-aware routing, offloading, and prefix caching
- Running models with these optimizations on any cloud (including BYOC) or on-prem cluster
Instead of spending time building your own inference system, you get an optimized one that handles GPU memory intelligently. With it, your models run faster, cheaper, and with higher throughput, and your engineering team can focus on AI development.
Conclusion#
VRAM is far more than a static storage specification. It is a dynamic resource that fluctuates with every token generated, every new user connected, and every millisecond of your inference runtime. Understanding the math behind model weights and KV cache growth is the first step to avoiding those deployment-day crashes.
The next step, namely solving it with quantization and different optimization techniques, is an engineering marathon.
That is why we built Bento. We believe your team should focus on building better AI products, not fighting with infrastructure issues.
If you want to run LLMs reliably, efficiently, and at scale:
- Join our community forum to learn from thousands of AI engineers
- Schedule a call with our team to explore your deployment needs
- Sign up for our Inference Platform and start serving LLMs today