Top Inference Platforms in 2026: A Buyer’s Guide for Enterprise AI Teams
Authors

Last Updated
Share

In the rush to ship AI products, many enterprise teams treat inference as an afterthought: a quick API call tacked on at the end of the build. But once workloads scale, that approach collapses. Costs spike. Performance becomes unpredictable. Infrastructure rigidly resists new models or compliance needs.
That’s where an inference platform comes in. It turns inference from a bottleneck into a strategic advantage by aligning performance, cost, and control with business goals. But here’s the catch: not all inference platforms are created equal.
This guide will walk you through what an inference platform is, the criteria that should guide your evaluation, and how the leading solutions stack up. You’ll see where each platform shines, and where it falls short. By the end, you’ll have a clear framework to choose the one that fits your workload, budget, and compliance needs.
What’s an inference platform, and why do you need one?#
At its core, an inference platform is the software layer that makes running machine learning and GenAI models in production simple. Instead of wrestling with servers, scaling issues, and infrastructure quirks, your team can focus on delivering AI-powered products that actually move the needle.
For enterprise teams, this layer matters because inference quality is product quality. If responses are slow, inaccurate, or unreliable, your end users feel it, and so does your business.
Many companies start with third-party LLM APIs because they’re fast to adopt and great for prototyping. But at scale, those shortcuts turn into structural liabilities. You face compliance risks when sensitive data leaves your VPC or on-prem environment. You’re locked into a single vendor’s GPUs, regions, and roadmap.
You can’t fine-tune for domain-specific SLAs. And without optimizations like KV caching or speculative decoding, performance and cost efficiency quickly plateau.
The result: unpredictable pricing, limited flexibility, and growing strategic risk. As Forrester analysts warn, vendor lock-in is escalating as cloud and AI providers consolidate into “platform of platforms,” making it even harder to switch once you’ve committed. These trade-offs highlight the importance of understanding the differences between serverless APIs and self-hosted inference when evaluating long-term options.
A robust inference platform solves these challenges. It gives you:
- Standardized deployments across hyperscalers, on-prem, and emerging neoclouds
- Heterogeneous compute management spanning GPU, CPU, and I/O-heavy workloads
- Advanced optimization to hit SLAs on latency, throughput, and cost-per-token
- Built-in security and compliance for regulated industries
- Comprehensive observability with inference-specific metrics
- Flexibility to adapt as new models and frameworks emerge
What to look for in an inference platform#
Choosing an inference platform isn’t just about what works today. It’s about building for long-term agility.
One early decision point involves the platform’s core approach:
- Model-centric platforms focus on pre-packaged endpoints with limited customization.
- Code-centric platforms let you integrate your own models, serving logic, and optimizations directly into the stack.
For enterprises that need flexibility, code-centric platforms typically provide more control over performance, cost, and compliance.
The right platform gives your team speed to ship, control to adapt, optimizations to meet demanding SLAs, and safeguards to stay compliant. Most importantly, it keeps you from getting locked into a single vendor’s roadmap.
Speed at every stage#
From proof-of-concept to production, time matters. Look for platforms that make it easy to:
- Spin up experiments with new models in minutes
- Optimize inference performance for your specific workload
- Move from prototype to production-ready deployment in days, not months
- Detect, diagnose, and resolve performance issues quickly
Every hour saved means faster time-to-value, less downtime risk, and the ability to out-iterate competitors.
Flexibility and control#
Enterprise workloads evolve quickly, so your platform needs to keep pace. Key indicators of flexibility include:
- Support for any model or framework, not just the vendor’s ecosystem
- Multiple serving modes, from real-time APIs to async jobs, batch processing, and multi-model pipelines
- Bring Your Own Cloud (BYOC), on-prem, and multi-cloud/hybrid deployment options
With these capabilities, you can adapt instantly to new model architectures, workload types, or compute providers without costly rebuilds or migrations.
Performance optimization#
At scale, efficiency drives ROI. Prioritize platforms with:
- Auto-scaling to match demand without over-provisioning
- Cold start minimization for faster response times
- Distributed inference support for large models
- LLM-specific features like KV cache management and speculative decoding
These optimizations help you meet strict SLA targets for latency and throughput while keeping $/token or per-inference costs sustainable.
Security and compliance#
Security can’t be an afterthought for enterprises, especially if you operate in regulated sectors like finance, healthcare, or government. Your platform should:
- Offer on-prem and air-gapped deployment options
- Meet industry-specific compliance frameworks such as SOC 2, HIPAA, or ISO
This ensures your data and models remain inside your secure boundary, reducing the risk of fines or breaches and shortening the approval cycle for sensitive workloads.
Scalability without lock-in#
The wrong platform can restrict you to a single cloud or hardware stack. The right one will:
- Handle heterogeneous workloads across CPU, GPU, and I/O-heavy tasks
- Allow you to switch compute vendors or regions without touching code
That flexibility protects against stranded investments and strengthens your position when negotiating hardware pricing.
Top inference platforms#
The market is crowded, but six platforms stand out for enterprise-scale inference. The matrix below shows how they compare on deployment flexibility, BYOC/on-prem support, optimization depth, and ideal use cases:
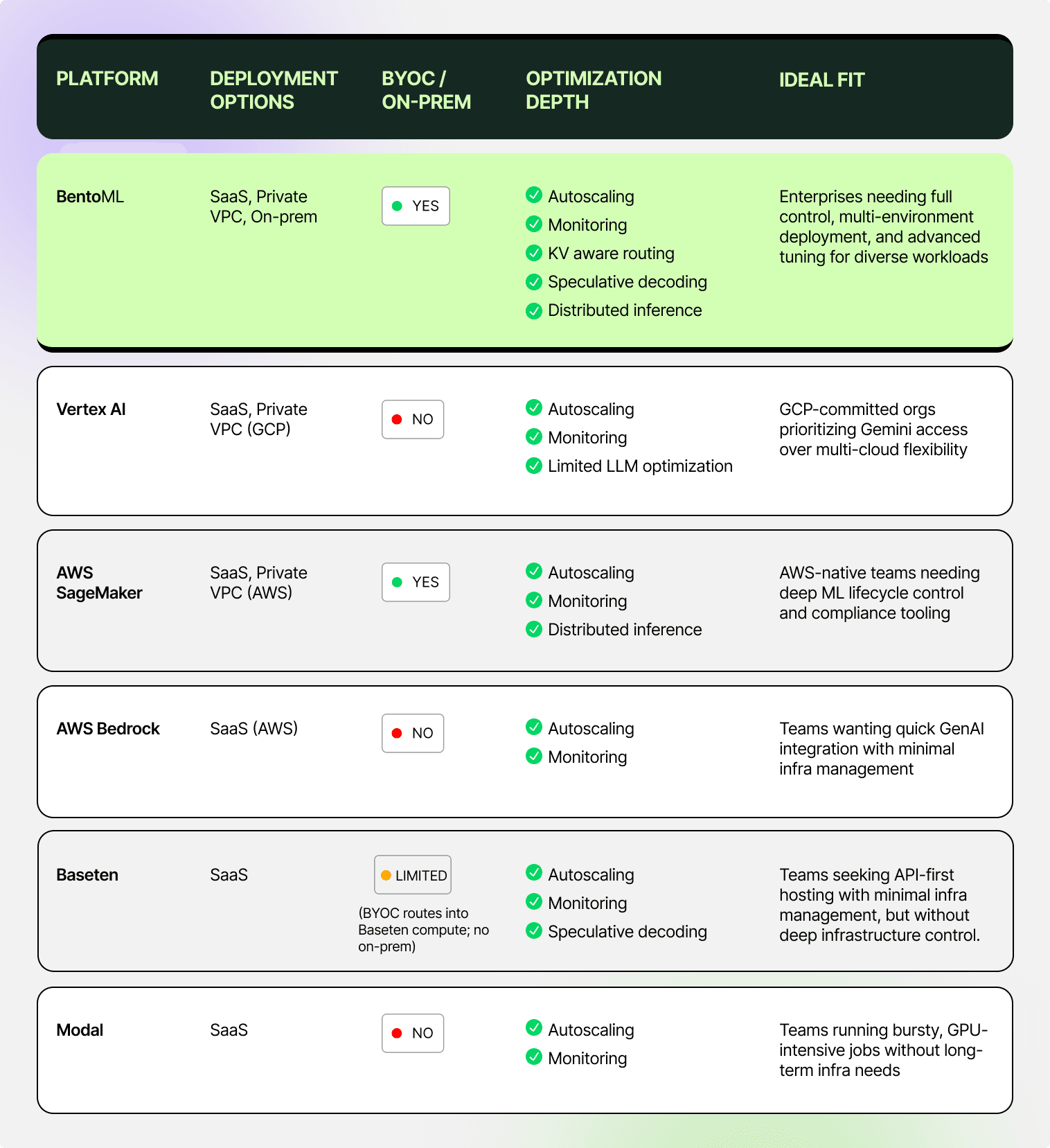
Next, we’ll take a closer look at each platform’s unique strengths and potential drawbacks, so you can match capabilities to your team’s priorities.
Bento#
The Bento Inference Platform is a code-centric solution that unifies model deployment across environments and gives enterprises fine-grained optimization for both traditional ML and GenAI models.
Notable features:
- Standardized “Bento” bundles for consistent deployment across on-prem, multi-cloud, or hybrid setups
- Flexible serving modes: real-time API, asynchronous jobs, batch processing, and multi-model pipelines
- Fast autoscaling with scale-to-zero support
- Built-in LLM optimization suite for KV cache management, batching, and distributed inference
- Full BYOC and on-prem support for maximum infrastructure control
Benefits:
- Predictable cost control and faster time-to-market
- Effective for both modern LLM workloads and legacy AI systems
Drawbacks:
- Requires some engineering involvement; not a fully hands-off API-only solution
Real-world results:
- Neurolabs accelerated time to market by 9 months, avoided two infra hires, and cut compute costs by up to 70% with auto-scaling and scale-to-zero.
Bottom line: Ideal for enterprises that need deep customization, advanced performance tuning, and true deployment portability, with full BYOC, native integration across all major hyperscalers and NeoClouds, and on-prem support for compliance.
Vertex AI#
Vertex AI is Google’s fully managed ML platform, designed for teams already committed to the Google Cloud ecosystem. It streamlines access to Gemini models and connects tightly with the broader GCP stack.
Notable features:
- Native access to Gemini family models with simple API integration
- Tight integration with GCP services such as BigQuery, Cloud Storage, and Vertex pipelines
- AutoML capabilities for custom model training and deployment
Benefits:
- Works natively with existing IAM, BigQuery, and Cloud Storage — no need to re-architect
- Simplified scaling within the Google Cloud ecosystem for both training and inference workloads
Drawbacks:
- GCP lock-in limits hybrid or multi-cloud flexibility
- TPU complexity adds operational friction for teams unfamiliar with Google-specific hardware
- Slow cold starts and costly GPUs, especially outside primary GCP regions
Bottom line: Best for GCP-committed organizations that want seamless access to Google’s AI models and services.
AWS SageMaker#
AWS SageMaker is Amazon’s end-to-end ML platform, covering the full lifecycle from model development to deployment. It’s designed for enterprises that need both scale and compliance within the AWS ecosystem.
Notable features:
- Deep integration with AWS services (S3, IAM, CloudWatch, etc.)
- Broad set of ML capabilities, including training, tuning, and deployment
- Strong compliance and security frameworks built in
Benefits:
- Enterprise-grade security and governance with AWS-native controls
- Wide service breadth, enabling ML teams to manage everything in one environment
Drawbacks:
- AWS vendor lock-in limits portability
- Steep learning curve, particularly for non-AWS-native teams
- GPU cost and availability challenges, including region-specific pricing constraints
Bottom line: Best for AWS-native enterprises prioritizing integration and compliance over multi-cloud flexibility.
AWS Bedrock#
AWS Bedrock focuses on fast access to foundation models through a serverless, API-first interface, making it one of the simplest routes to adding GenAI capabilities into applications.
Notable features:
- API-first access to Anthropic Claude, Amazon Titan, and other pre-trained foundation models
- Fully serverless architecture with instant scaling
- No need to manage infrastructure or GPU provisioning
Benefits:
- Minimal setup and infrastructure management
- Rapid integration of generative AI into applications
Drawbacks:
- Limited customization compared to code-centric platforms
- Primarily focused on generative AI, less suited for traditional ML or hybrid workloads
Bottom line: Best for teams that want quick, serverless access to GenAI without managing infrastructure.
Baseten#
Baseten offers a streamlined way to deploy ML models as APIs, appealing to teams that want speed and simplicity over infrastructure control.
Notable features:
- Model deployment via APIs and Truss code packaging
- BYOC limited to routing workloads into Baseten’s own compute (not true self-hosting or on-prem)
Benefits:
- Low-friction, API-first deployment approach
- Fast path from development to production endpoints
Drawbacks:
- No on-prem deployment options
- Hybrid model centers on BYOC → Baseten compute
- Recent product direction emphasizes selling Baseten’s own compute and APIs, reducing flexibility for enterprise infra strategies
Bottom line: Best for smaller teams that want a quick API-based hosting solution, but less suited for enterprises that need compliance-ready, environment-controlled inference.
Modal#
Modal provides access to on-demand GPUs with a simple pay-as-you-go model, making it attractive for bursty workloads that don’t justify permanent infrastructure.
Notable features:
- Pay-as-you-go GPU access with simple provisioning
- Minimal setup process for deployment and scaling
Benefits:
- Cost-effective for variable or bursty workloads
- Quick access to compute for experimentation or short-term projects
Drawbacks:
- No BYOC or on-prem options
- Less suitable for sustained, high-volume enterprise workloads
Bottom line: A good match for teams that value GPU availability and ease of use over infrastructure ownership or advanced customization.
How to apply this buyer’s guide#
Choosing the right inference platform isn’t about chasing the longest feature list, but finding the best fit for your team’s priorities.
Start by shortlisting platforms that meet your top three non-negotiables, whether that’s deployment flexibility, peak performance, airtight security, or a combination of all three.
Next, use the comparison matrix as your scorecard and evaluate where each option meets, exceeds, or falls short of your must-haves. This makes trade-offs explicit and helps you avoid surprises after adoption.
Finally, map technical capabilities directly to your business requirements, from SLA guarantees and compliance obligations to budget constraints. A platform that’s technically impressive but misaligned with your operational model will slow you down rather than speed you up.
Here's how to use technical requirements to guide platform selection:
- Unified, cloud-agnostic deployment: Look for portable packaging, like Bento bundles, that run seamlessly across multiple environments.
- Avoiding compute lock-in: Prioritize platforms with BYOC and multi-cloud/on-prem deployment support.
- Multiple serving modes: Ensure the platform supports real-time APIs, asynchronous jobs, batch processing, and multi-model pipeline workflows.
- Performance at scale: Verify features like auto-scaling, fast cold starts, and LLM-specific tuning.
- Complex pipelines: Require support for multi-step, heterogeneous workloads that can span different model types and hardware.
- Heavy developer/MLOps use: Check for robust SDKs, CLI tools, local parity, and integrated CI/CD.
- Deep observability: Confirm the availability of LLM-specific metrics, anomaly detection, and other monitoring tools.
- Regulated environments: Look for BYOC/on-prem deployment options and a strong compliance track record.
This approach ensures your platform choice supports long-term business goals rather than short-term convenience.
Why Bento sets the standard for agility and control#
The inference platforms above each excel in specific areas, but often require trade-offs. The Bento Inference Platform addresses the full spectrum of enterprise needs.
- Speed: Package and deploy models in minutes with Bento bundles, then optimize performance through autoscaling and fast cold starts.
- Flexibility: Cloud-agnostic packaging and multi-cloud/on-prem support mean no vendor lock-in.
- Performance: LLM-specific features like KV cache management, speculative decoding, and distributed inference help meet strict SLAs at lower cost.
- Security: BYOC and on-prem options keep data and models in your environment, supporting SOC 2 and industry regulations.
- Scalability: Orchestrate heterogeneous workloads across CPUs, GPUs, and I/O-heavy tasks; support multi-model pipelines for RAG, agentic, and multi-modal use cases.
- Developer-first: Python SDK, CLI, and APIs for rapid development, with integrated CI/CD, rollback, and built-in observability for LLM-specific metrics.
These capabilities aren’t just theoretical. At LINE, engineers directly integrated the Bento Inference Platform with MLflow and standardized multi-model serving patterns, achieving faster, repeatable deployments that shortened iteration cycles.
The platform delivers a single, code-centric layer that unifies deployment, optimization, and compliance, giving enterprises speed and flexibility without sacrificing control.
Schedule a call with us today and learn how to deploy inference your way.