DeepSeek-OCR Explained: How Contexts Optical Compression Redefines AI Efficiency
Authors

Last Updated
Share

DeepSeek has once again set the AI world buzzing with its new model, DeepSeek-OCR.
At first glance, DeepSeek-OCR looks like just another vision language model (VLM). But as their research paper shows, it is much more than that. DeepSeek-OCR introduces a completely new way to think about how AI models store, process, and compress information.
Rather than simply improving OCR, it challenges a fundamental assumption: LLMs must process information as long sequences of text tokens. DeepSeek-OCR shows that this doesn’t have to be the case. A model can “see” information instead of just reading it, achieving the same understanding with a fraction of the computation.
In this blog post, we’ll look at:
- What Contexts Optical Compression is
- How DeepSeek-OCR works
- Why it matters for the future of long-context and efficient LLMs
- How to deploy DeepSeek-OCR with BentoML
What is Contexts Optical Compression?#
LLMs today face a growing computational bottleneck when handling long pieces of text. Every token they process consume resources: floating-point operations per second (FLOPs), memory, time, and energy. A 10,000-token article means 10,000 discrete processing steps. That’s like forcing a model to read every single word in sequence, even when much of the content is repetitive or predictable.
DeepSeek-OCR rethinks what a token can be with Contexts Optical Compression. Instead of treating long text sequences as endless strings of small, low-information text tokens, it uses the visual modality as a more efficient compression channel for textual information.
In this framework, it compresses the same content into a smaller set of dense visual tokens. Each visual token carries much richer information, such as typography, layout, and spatial relationships between words. This allows the model to encode and understand entire chunks of text at once.
The result: The model achieved the same semantic understanding with an order-of-magnitude fewer computation steps. What once required 1,000 text tokens might now be represented by just 100 visual ones. This can reduce processing time and cost dramatically while preserving context.
DeepSeek-OCR is thus more than just an open-source OCR model. It is a proof of concept for a new paradigm in AI efficiency: let models see information instead of merely reading it.
Even Andrej Karpathy noted that DeepSeek-OCR raises a deeper question: are pixels better inputs to LLMs than text? He suggests that text tokens might be inherently wasteful and that “historical baggage” could eventually be replaced by visual inputs for efficiency.
How does DeepSeek-OCR work?#
DeepSeek-OCR features a unified end-to-end VLM architecture built around two brains that work together: a visual encoder and a language decoder.
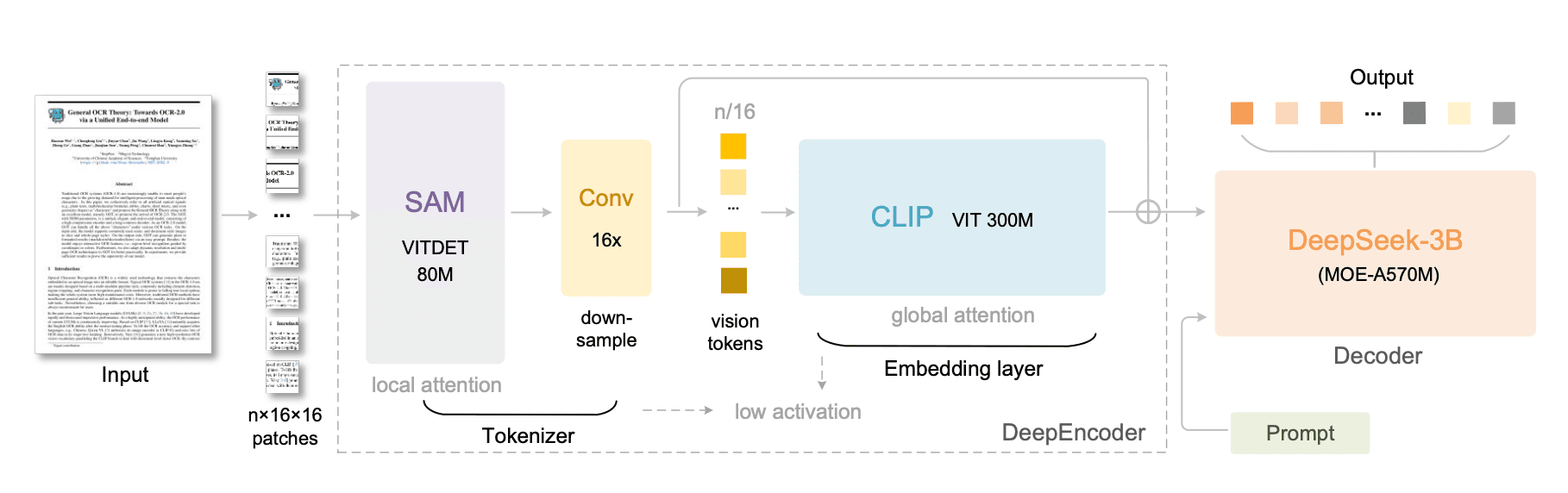
DeepEncoder#
The DeepEncode is where the compression happens. It handles high-resolution inputs more efficiently in terms of memory and token counts.
The DeepSeek team built it from the ground up because no existing open-source encoder met their requirements. They needed a model that could:
- Process high resolutions efficiently
- Maintain low activation at high resolutions
- Create a small number of vision tokens
- Support multi-resolution inputs
- Keep a moderate parameter count
To meet these conditions, the team designed a 380M parameter encoder that achieves high compression ratios and can output a manageable number of vision tokens. It combines three main components:
- SAM-base (80M) for visual perception using window attention
- CLIP-large (300M) for knowledge with dense global attention
- A 16× Token Compressor bridges the two, capable of reducing thousands of patch tokens into a few hundred vision tokens
DeepSeek-3B-MoE Decoder#
Once the encoder compresses the input into visual tokens, the DeepSeek-3B-MoE Decoder turns them back into text.
This decoder uses a MoE design. During inference, it activates only 6 of 64 experts plus 2 shared ones, totaling about 570M activated parameters. This gives it the power of a 3B model but the inference cost of one under 600M, an ideal balance between performance and efficiency.
The decoder receives the vision tokens and prompts, and generates the final output, including chemical structures and planar geometric figures.
How well does DeepSeek-OCR perform?#
DeepSeek-OCR demonstrates strong efficiency and accuracy across benchmarks.
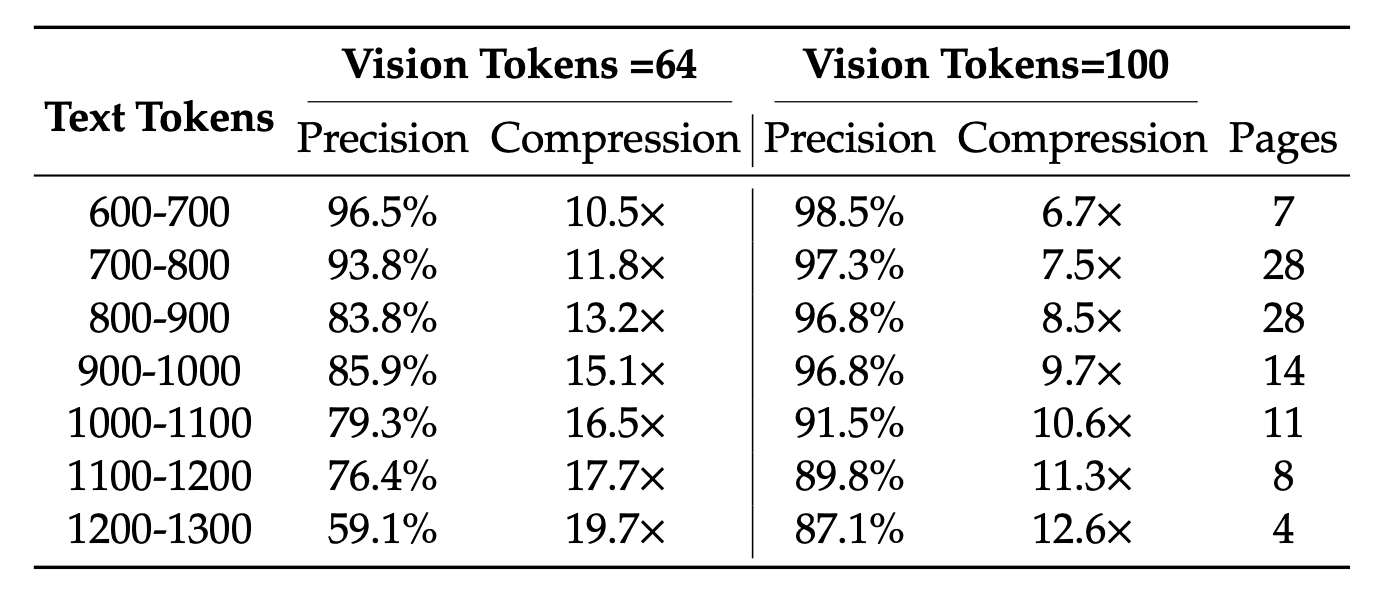
At a 10× compression ratio, it retains around 97% accuracy. Even at higher compression levels (up to 20×), it can still produce usable results at roughly 60% accuracy.
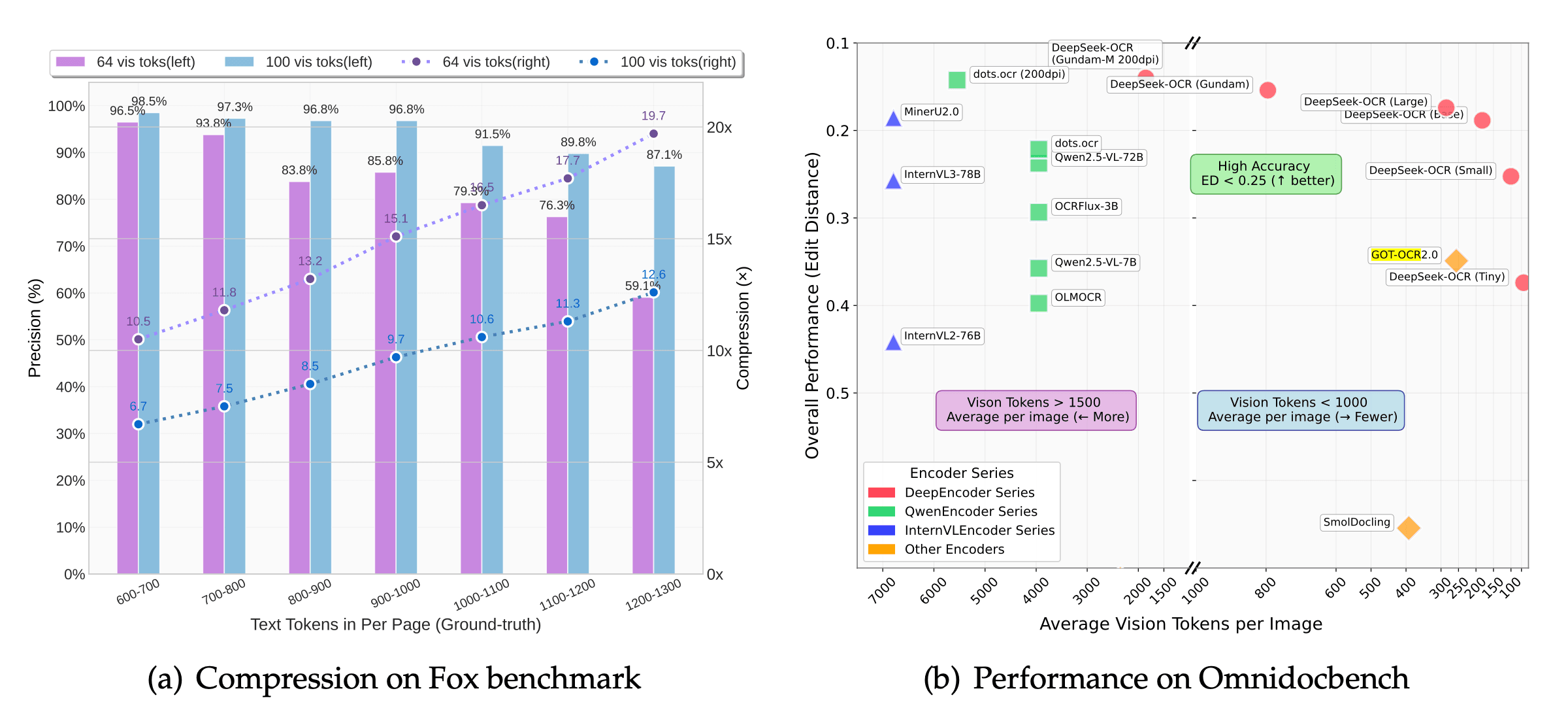
On OmniDocBench, a leading benchmark for document understanding, DeepSeek-OCR outperforms established baselines such as GOT-OCR 2.0 and MinerU 2.0, achieving higher accuracy with far fewer tokens.
In deployment, it also proves highly practical. With a single A100 40GB GPU, DeepSeek-OCR can process more than 200K pages per day. This makes it a viable solution for large-scale document processing and training data generation for LLMs and VLMs.
Why DeepSeek-OCR matters?#
By turning text into visual representations, DeepSeek-OCR shows that LLMs don’t always have to process information through text tokens. A single image can carry far more meaning with far fewer tokens. This idea opens up a promising direction for building long-context and more efficient LLMs.
What this means:
- Massive efficiency gains: DeepSeek-OCR can represent the same content using up to 20× fewer tokens, cutting computation time and memory usage.
- Lower cost: With fewer tokens to process, models become cheaper and quicker to run, especially at scale.
- Open source: The model code and weights are public and available for anyone to experiment and extend.
- Potential for long-context LLMs: Vision-based tokens could help future LLMs handle far more context (theoretically unlimited context).
For the last point, the paper introduces a fascinating concept inspired by human memory. As human beings, we gradually forget details while keeping what’s important. DeepSeek-OCR proposes something similar; it uses optical compression to shrink and blur older conversation history over time:
- Recent information remains sharp and detailed.
- Older context fades and consumes fewer resources.
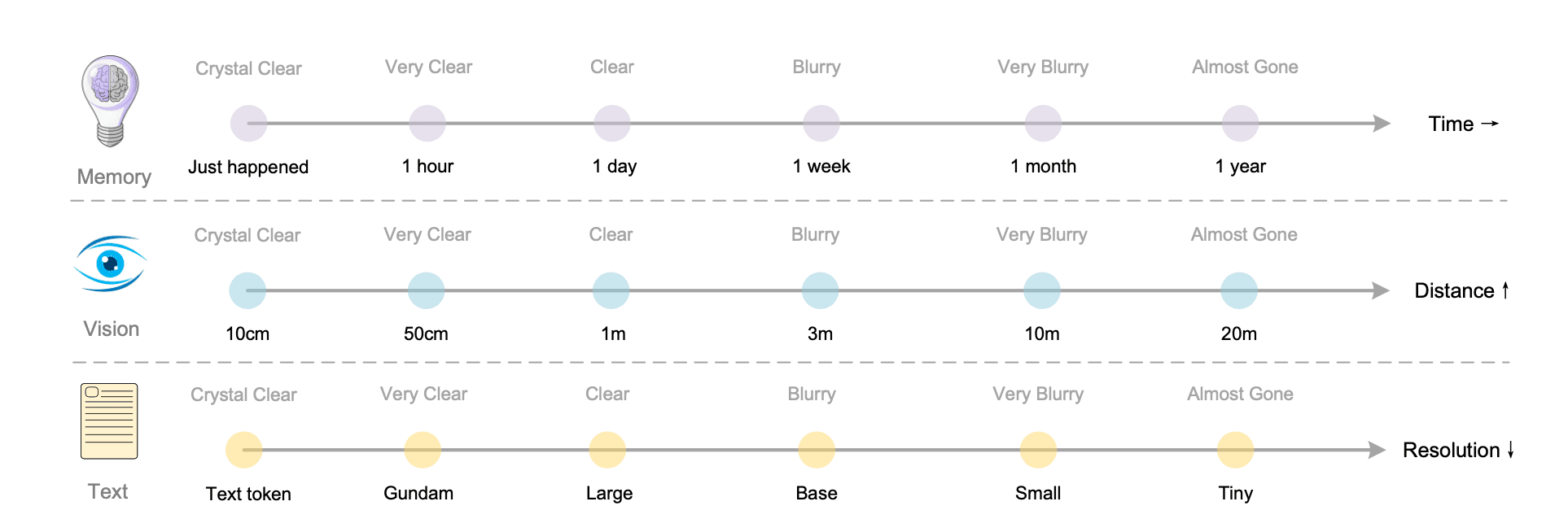
This “visual forgetting” mechanism could enable models to manage ultra-long conversations more efficiently. It preserves what matters most while letting less relevant details fade naturally. It’s an early but promising step toward more powerful multimodal AI and theoretically unlimited context architectures.
Deploying DeepSeek-OCR with BentoML#
BentoML allows you to deploy DeepSeek-OCR in your private cloud or on-prem environment with custom inference logic.
Here is an example of serving DeepSeek-OCR with vLLM and BentoML:
PROMPT_FREE_OCR = "<image>\nFree OCR." # for doc-to-markdown with layout grounding: # PROMPT_FREE_OCR = "<image>\n<|grounding|>Convert the document to markdown." # Define runtime bento_image = bentoml.images.Image(python_version="3.12") \ .python_packages("Pillow", "numpy<2.3") \ .run('pip install -U vllm --pre --extra-index-url https://wheels.vllm.ai/nightly') # Create a BentoML Service @bentoml.service( name="deepseek-ocr-vllm", image=bento_image, resources={ "gpu": 1, "gpu_type": "nvidia-a100-80gb", }, ) class DeepSeekOCR: # Load model from HF model_path = HuggingFaceModel("deepseek-ai/DeepSeek-OCR") def __init__(self) -> None: # Logic to serve with vLLM here self.llm = LLM( model=self.model_path, ... ) self.sampling = SamplingParams( ... ) # Define APIs to process images @bentoml.api def ocr_image(self, image: PILImage, prompt: str = PROMPT_FREE_OCR) -> str: # convert to RGB if image.mode != "RGB": image = image.convert("RGB") model_input = [{"prompt": prompt, "multi_modal_data": {"image": image}}] outputs = self.llm.generate(model_input, self.sampling) return outputs[0].outputs[0].text @bentoml.api def ocr_batch(self, images: list[PILImage], prompt: str = PROMPT_FREE_OCR) -> list[str]: rgb_images = [(img if img.mode == "RGB" else img.convert("RGB")) for img in images] model_input = [{"prompt": prompt, "multi_modal_data": {"image": img}} for img in rgb_images] outputs = self.llm.generate(model_input, self.sampling) return [o.outputs[0].text for o in outputs]
After you deploy it to BentoCloud, you will obtain a secure and scalable API.
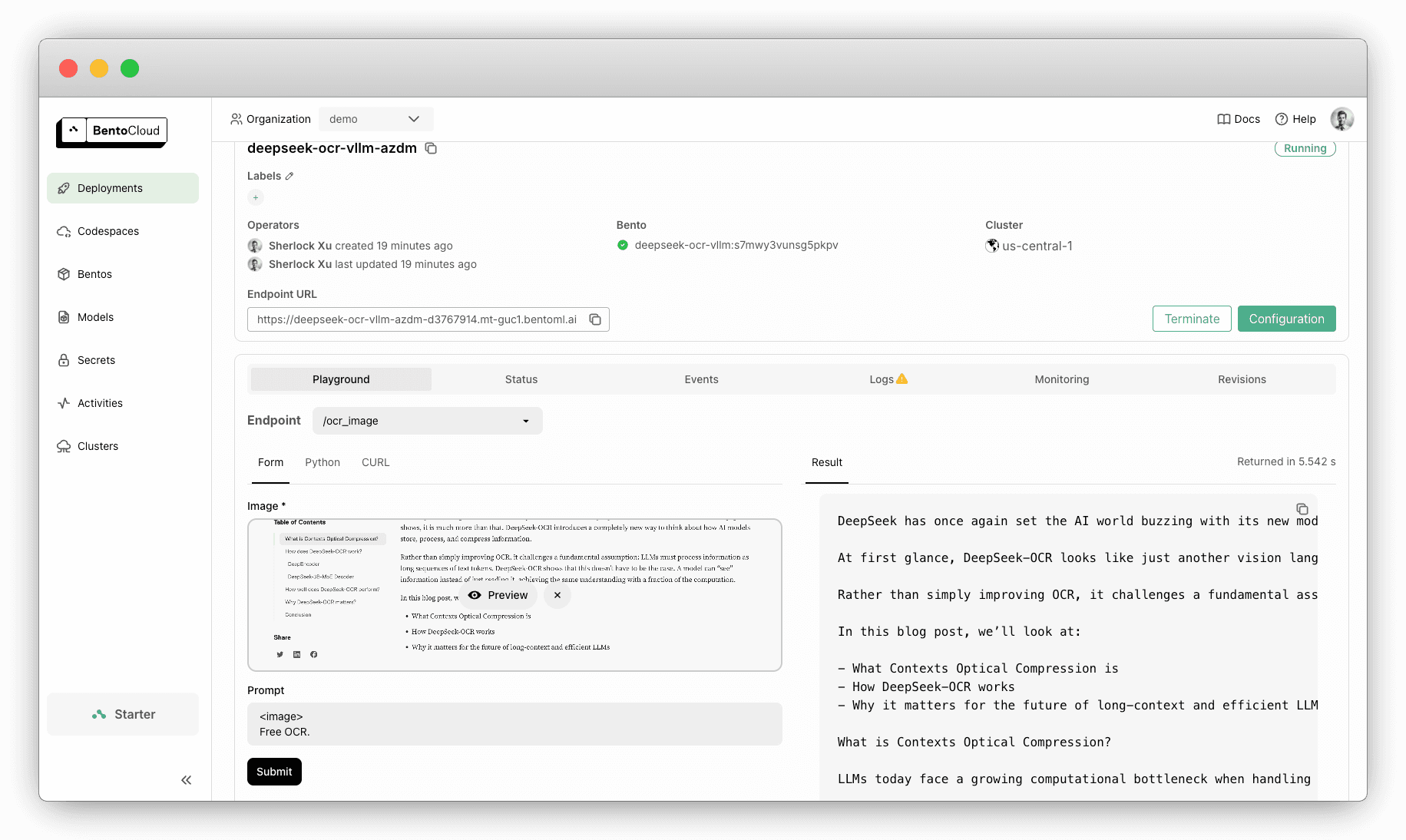
Check out the complete code here.
Conclusion#
DeepSeek-OCR is more than an OCR breakthrough. It’s a glimpse into a new way of thinking about efficiency and memory in AI systems. By replacing text tokens with compact visual representations, it redefines how models can scale, reason, and remember.
Learn more:
- Join our community forum to connect with other builders
- Contact us if you need help integrating DeepSeek-OCR into your own workflows
- Sign up for our Inference Platform to build, deploy, and scale AI applications with DeepSeek-OCR