llm-optimizer: An Open-Source Tool for LLM Inference Benchmarking and Performance Optimization
Authors



Last Updated
Share

At Bento, we work to help AI teams deploy and scale models with tailored optimization. That means giving them the ability to tune performance for their specific use cases with ease and speed, so they can achieve better price-performance ratios.
As part of that effort, we’re excited to introduce llm-optimizer, an open-source tool for benchmarking and optimizing LLM inference. It works across multiple inference frameworks and supports any open-source LLM.
Unlike traditional benchmarking tools that only generate raw numbers, llm-optimizer allows you to define constraints, such as “TTFT under 200ms” or “P99 ITL below 10ms.” This makes it easy to quickly identify the configurations that meet your specific requirements without endless trial and error.
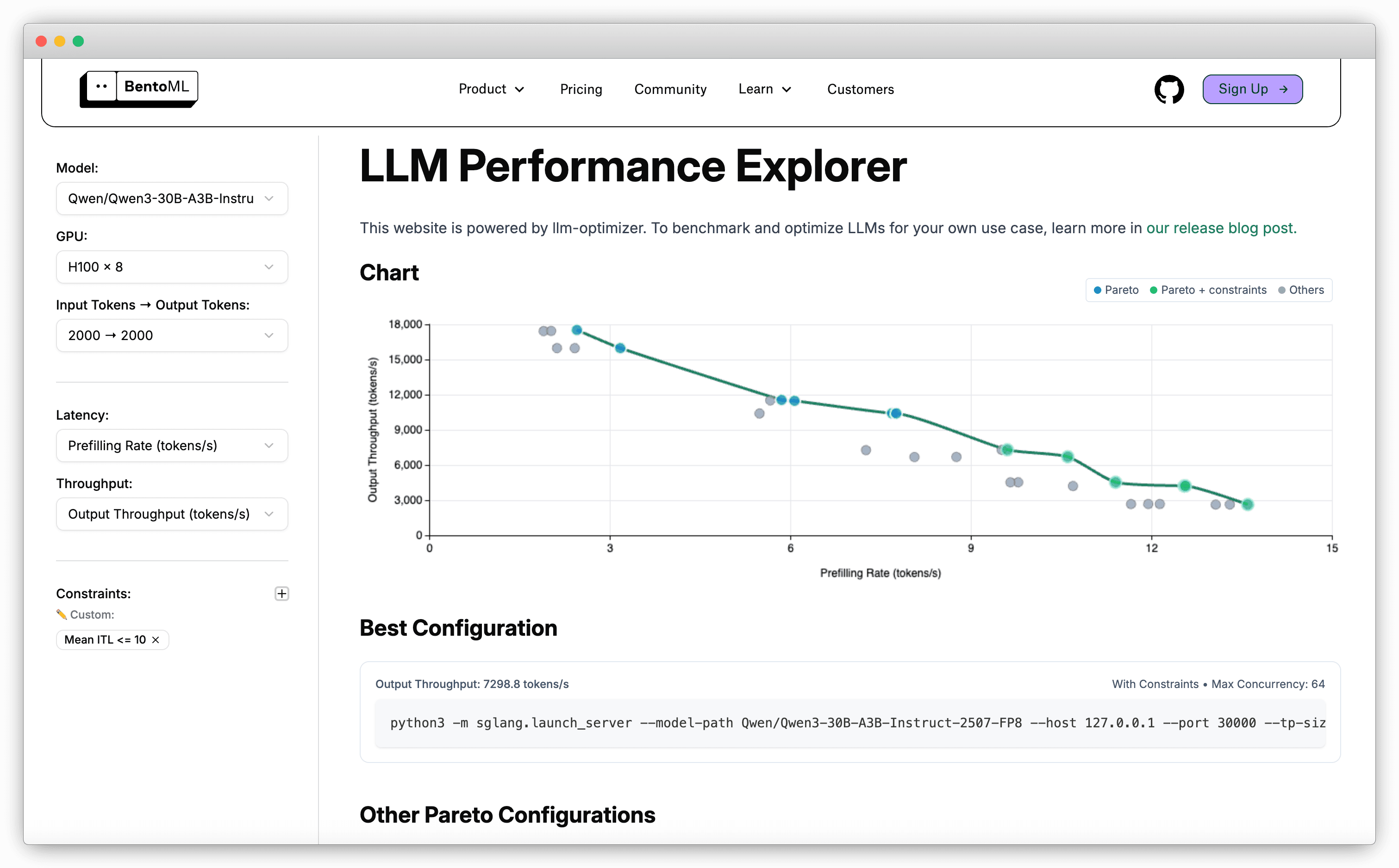
At the same time, we’re launching the LLM Performance Explorer, a companion website powered by llm-optimizer. It lets you browse LLM benchmark results directly without running experiments yourself. You can compare different configurations, apply constraints, and quickly see which setup works best for your specific use case.
Motivation#
When it comes to self-hosting LLMs, performance tuning can be very tricky. There are so many factors to balance:
- Server parameters: Parallelism strategies (e.g., data, tensor, pipeline), batch sizes, caching strategies, etc.
- Client parameters: Request rates, concurrency levels, number of prompts, etc.
- Framework differences: Each inference framework (vLLM, SGLang, TensorRT-LLM, etc.) has its own optimization strategies and tuning knobs.
- Workload variations: Different models, input lengths, and request patterns require different optimizations.
For most AI teams, the only way to figure it out has been trial and error: endless tests, parameter tweaks, and results that are hard to compare. It’s tedious, time-consuming, and often error-prone.
This led us to build llm-optimizer. We want to provide engineers a systematic way to test configurations, and give them a clear view of what really works with just a few commands. More importantly, it must support constraint filtering, so that engineers don’t need to sift through mountains of raw result data. This means they can focus on the right parameters for their specific optimization goals. Ultimately, engineers spend less time tuning and more time building.
Key features#
llm-optimizer was built to take the tedious manual work out of LLM performance optimization. You can run structured experiments, apply constraints, and visualize results in one place - all with a few commands.
Systematic parameter testing#
llm-optimizer supports systematic tests of different combinations of server and client parameters across multiple inference frameworks. It works with any open-source LLM. Simply provide the Hugging Face model tag.
Here is an example with vLLM:
llm-optimizer \ --framework vllm \ --model meta-llama/Llama-3.1-8B-Instruct \ --server-args "tensor_parallel_size=[1,2];max_num_batched_tokens=[4096,8192]" \ --client-args "max_concurrency=[32,64];num_prompts=1000;dataset_name=sharegpt" \ --output-json vllm_results.json
Parameters like tensor_parallel_size and max_num_batched_tokens come directly from the respective frameworks (currently support vLLM and SGLang). If you’re familiar with other native parameters, you can add them as well.
Here is another example with SGLang:
llm-optimizer \ --framework sglang \ --model meta-llama/Llama-3.1-8B-Instruct \ --server-args "tp_size*dp_size=[(1,4),(2,2),(4,1)];chunked_prefill_size=[2048,4096]" \ --client-args "max_concurrency=[32,64,128];num_prompts=[500,1000]" \ --output-dir optimization_results \ --output-json results.json \ --continue \ --rest 10 \ --warmup-requests 3
This command generates 36 unique test runs:
- 3 tensor/data parallelism combinations × 2 prefill sizes = 6 server configs
- 3 concurrency values × 2 prompt counts = 6 client configs
- 6 × 6 = 36 total configurations, each with 3 warmup requests and a 10-second rest between runs
This means 36 results you can analyze or filter further using constraints.
Constraint settings#
Not every benchmark result is useful. What really matters is finding the configuration that meets your performance goals, especially when you have specific SLOs for inference. Without filtering, large test runs can generate too much noise and make it harder to analyze results.
With llm-optimizer, you can:
- Filter results to only include configurations that meet your requirements
- Identify optimal setups for latency or throughput targets
The following is a typical use case where you can optimize for chatbots or other low-latency workloads.
llm-optimizer \ --framework vllm \ --model meta-llama/Llama-3.1-8B-Instruct \ --server-args "tensor_parallel_size*data_parallel_size=[(1,2),(2,1)];max_num_seqs=[16,32,64]" \ --client-args "max_concurrency=[8,16,32];num_prompts=500" \ --constraints "ttft<200ms;itl:p99<10ms" \ --output-json chat_optimized.json
This command will only return results where:
- Time to First Token (TTFT) is below 200ms
- 99% of Inter-Token Latency (ITL) are below 10ms
Comprehensive benchmarking results#
Benchmarks are only useful if the results tell you something actionable. llm-optimizer provides detailed inference-specific metrics, giving you a clear view of how your model behaves under different conditions.
For LLMs, performance is best measured at the token level. Key metrics include:
- Time to First Token (TTFT): How long it takes for the first response token to appear after a request is sent
- Inter-Token Latency (ITL): The average time between tokens in a response.
- Input/Output Token Throughput: How many tokens are processed/generated per second during the benchmark.
In addition, you also get traditional request-level metrics such as end-to-end latency, request throughput, and optimal concurrency. These measurements combined help you make trade-offs for your performance goals.
Results are output in JSON, easy to filter and compare. Here’s a simplified example:
[ { "config": { "client": { "max_concurrency": 8, "num_prompts": 1000, "dataset_name": "sharegpt", "sharegpt_output_len": 256 }, "server": { "tensor_parallel_size": 1, "max_num_batched_tokens": 4096, "max_num_seqs": 16 }, "server_args": [ "--tensor-parallel-size=1", "--max-num-batched-tokens=4096", "--max-num-seqs=16" ] }, "results": { "backend": "vllm", "dataset_name": "sharegpt", "max_concurrency": 8, "total_input_tokens": 296523, "total_output_tokens": 256000, "total_output_tokens_retokenized": 255910, "request_throughput": 2.323720163971585, "input_throughput": 689.0364741813463, "output_throughput": 594.8723619767258, "mean_e2e_latency_ms": 3441.463320413, "median_e2e_latency_ms": 3413.3226294999304, "std_e2e_latency_ms": 130.47813647173385, "p99_e2e_latency_ms": 4003.9951376500244, ... }, "cmd": "vllm serve meta-llama/Llama-3.1-8B-Instruct --host 127.0.0.1 --port 8000 --tensor-parallel-size=1 --max-num-batched-tokens=4096 --max-num-seqs=16" }, // More results below
Performance estimation#
Sometimes you want to understand how a model will perform before running a full benchmark. Maybe you don’t have the required hardware, your time is limited, or you just want a quick estimate of what to expect. llm-optimizer supports performance estimation that analyzes a model and generates theoretical results without running live tests.
Here is an example:
llm-optimizer estimate \ --model meta-llama/Llama-3.1-8B-Instruct \ --input-len 1024 \ --output-len 512 \ --gpu A100 \ --num-gpus 2
This command:
- Analyzes the 8B Llama model on 2x A100 GPUs
- Estimates performance for 1024 input + 512 output tokens
- Shows best latency and throughput configurations
- Provides roofline analysis and identifies bottlenecks
- Generates the commands to run actual benchmarks with SGLang and vLLM
Expected output:
=== Configuration === Model: meta-llama/Llama-3.1-8B-Instruct GPU: 2x A100 Precision: fp16 Input/Output: 1024/512 tokens Target: throughput Fetching model configuration... Model: 8029995008.0B parameters, 32 layers === Performance Analysis === Best Latency (concurrency=1): TTFT: 43.1 ms ITL: 2.6 ms E2E: 1.39 s Best Throughput (concurrency=512): Output: 18873.3 tokens/s Input: 23767.8 tokens/s Requests: 14.24 req/s Bottleneck: Memory === Roofline Analysis === Hardware Ops/Byte Ratio: 142.5 ops/byte Prefill Arithmetic Intensity: 52205.5 ops/byte Decode Arithmetic Intensity: 50.9 ops/byte Prefill Phase: Compute Bound Decode Phase: Memory Bound === Concurrency Analysis === KV Cache Memory Limit: 688 concurrent requests Prefill Compute Limit: 8 concurrent requests Decode Capacity Limit: 13 concurrent requests Theoretical Overall Limit: 8 concurrent requests Empirical Optimal Concurrency: 16 concurrent requests === Tuning Commands === --- SGLANG --- Simple (concurrency + TP/DP): llm-optimizer --framework sglang --model meta-llama/Llama-3.1-8B-Instruct --gpus 2 --host 127.0.0.1 --server-args "tp_size*dp_size=[(1, 2), (2, 1)]" --client-args "num_prompts=1000;dataset_name=sharegpt;random_input=1024;random_output=512;num_prompts=1000;max_concurrency=[256, 512, 768]" --output-dir tuning_results --output-json tuning_results/config_1_sglang.json Advanced (additional parameters): llm-optimizer --framework sglang --model meta-llama/Llama-3.1-8B-Instruct --gpus 2 --host 127.0.0.1 --server-args "tp_size*dp_size=[(1, 2), (2, 1)];chunked_prefill_size=[1434, 2048, 2662];schedule_conservativeness=[0.3, 0.6, 1.0];schedule_policy=fcfs" --client-args "num_prompts=1000;dataset_name=sharegpt;random_input=1024;random_output=512;num_prompts=1000;max_concurrency=[256, 512, 768]" --output-dir tuning_results --output-json tuning_results/config_1_sglang.json --- VLLM --- Simple (concurrency + TP/DP): llm-optimizer --framework vllm --model meta-llama/Llama-3.1-8B-Instruct --gpus 2 --host 127.0.0.1 --server-args "tensor_parallel_size*data_parallel_size=[(1, 2), (2, 1)]" --client-args "num_prompts=1000;dataset_name=sharegpt;random_input=1024;random_output=512;num_prompts=1000;max_concurrency=[256, 512, 768]" --output-dir tuning_results --output-json tuning_results/config_1_vllm.json Advanced (additional parameters): llm-optimizer --framework vllm --model meta-llama/Llama-3.1-8B-Instruct --gpus 2 --host 127.0.0.1 --server-args "tensor_parallel_size*data_parallel_size=[(1, 2), (2, 1)];max_num_batched_tokens=[1024, 1177, 1331]" --client-args "num_prompts=1000;dataset_name=sharegpt;random_input=1024;random_output=512;num_prompts=1000;max_concurrency=[256, 512, 768]" --output-dir tuning_results --output-json tuning_results/config_1_vllm.json
If you’re not sure what parameters to provide, you can use the interactive mode. It walks you through the setup step by step and generates the same results as if you had provided them directly:
$ llm-optimizer estimate --interactive === LLM Performance Estimation (Interactive Mode) === 🤖 Model Selection Popular options: meta-llama/Llama-3.2-1B, meta-llama/Meta-Llama-3-8B, meta-llama/Meta-Llama-3-70B HuggingFace model ID: meta-llama/Llama-3.2-1B 📏 Sequence Length Configuration Typical values: 512 (short), 1024 (medium), 2048 (long), 4096 (very long) Input sequence length (tokens) [1024]: 512 Output sequence length (tokens) [512]: 512 ## More options...

Interactive user interface#
Raw numbers are useful, but they’re much easier to interpret when you can see patterns and trade-offs. llm-optimizer offers a visualization tool that turns benchmark results into interactive dashboards.
After running benchmarks, you don’t have to parse JSON by hand. Simply launch a local dashboard and explore your results visually:
# Visualize results with Pareto frontier analysis llm-optimizer visualize --data-file results.json --port 8080 # Combine multiple result files llm-optimizer visualize --data-file "sglang_results.json,vllm_results.json" --port 8080
The dashboard will be served at http://localhost:8080/pareto_llm_dashboard.html.
Note: This feature is still experimental, and we’ll continue improving it in the coming days. For visualized results, check out the LLM Performance Explorer.
Getting started#
Install llm-optimizer:
git clone https://github.com/bentoml/llm-optimizer.git pip install -e .
Run a quick estimation:
llm-optimizer estimate \ --model meta-llama/Llama-3.1-8B-Instruct \ --gpu A100 \ --num-gpus 4 \ --input-len 1024 \ --output-len 512
Run your first benchmark (make sure you have enough GPU resources):
llm-optimizer \ --framework vllm \ --model meta-llama/Llama-3.1-8B-Instruct \ --server-args "tensor_parallel_size*data_parallel_size=[(1,4),(2,2),(4,1)]";max_num_seqs=[16,32,64]" \ --client-args "max_concurrency=[8,16,32];num_prompts=500" \ --constraints "ttft<200ms;itl:p99<10ms" \ --output-json latency_optimized.json
LLM inference optimization doesn’t have to mean endless trial and error. llm-optimizer makes it easy to benchmark different configurations, apply constraints, estimate performance, and visualize results — all with a few commands.
More resources:
- View the benchmark results of top open-source LLMs on the LLM Performance Explorer
- Join our community forum to connect with other AI engineers and share feedback
- Read our LLM Inference Handbook for deeper dives into performance optimization
- Schedule a call with our experts to discuss your use case and performance goals