Get 3× Faster LLM Inference with Speculative Decoding Using the Right Draft Model
Authors




Last Updated
Share

LLMs are powerful, but they’re slow during inference. That’s because they’re trained with an autoregressive pattern: generating the next token based on all the previous ones. During inference, this means every new token requires a full forward pass through the model, followed by sampling and then appending that token to the input for the next step. This process is inherently sequential, meaning the model can’t compute future tokens ahead even if the GPU is idle. This leads to high Inter-Token Latency (ITL) and poor GPU utilization.
Speculative decoding offers a solution. By having a small draft model predict several tokens in advance, and letting a larger target model verify them in parallel, you can accelerate the token generation process.
In practice, however, we found speculative decoding only delivers the expected speedup if the draft model’s distribution matches closely with the target model. The key is using the right draft model for your workload, which in many real-world cases means training one on your own data.
In this post, we’ll walk through:
- How speculative decoding works and when it helps
- Why acceptance rate is the performance bottleneck
- Our benchmarks with vLLM, SGLang, and EAGLE 3
- Why training a custom draft model is helpful for real-world speedups
What is speculative decoding#
Speculative decoding is an inference-time optimization technique that speeds up LLM token generation without sacrificing output quality. It’s inspired by the concept of speculative execution, where operations are computed in parallel ahead of time and discarded if unneeded.
This technique builds on two key observations about LLM inference:
- LLM inference is memory-bound. Hardware like GPUs can perform hundreds of trillions of operations per second, but their memory bandwidth is much lower. That means these chips often have unused compute capacity while waiting on memory. For transformer-based LLMs, they can only perform a few operations per byte of memory read during inference, which means compute is underutilized.
- Some tokens are easier to predict than others. Many next tokens are obvious from context and can be easily handled by a small model.
To take advantage of these facts, speculative decoding uses a draft-then-verify paradigm:
- Draft model: A smaller, faster model proposes a draft sequence of tokens.
- Target model: The original larger model verifies the draft’s tokens at once and decides which to accept.
Note: This draft-then-verify idea was first introduced by Stern et al. (2018), and later extended into a statistically grounded technique called speculative sampling by DeepMind. Speculative decoding is the application of speculative sampling to inference from autoregressive models, like transformers.
Here is how it works in more details:
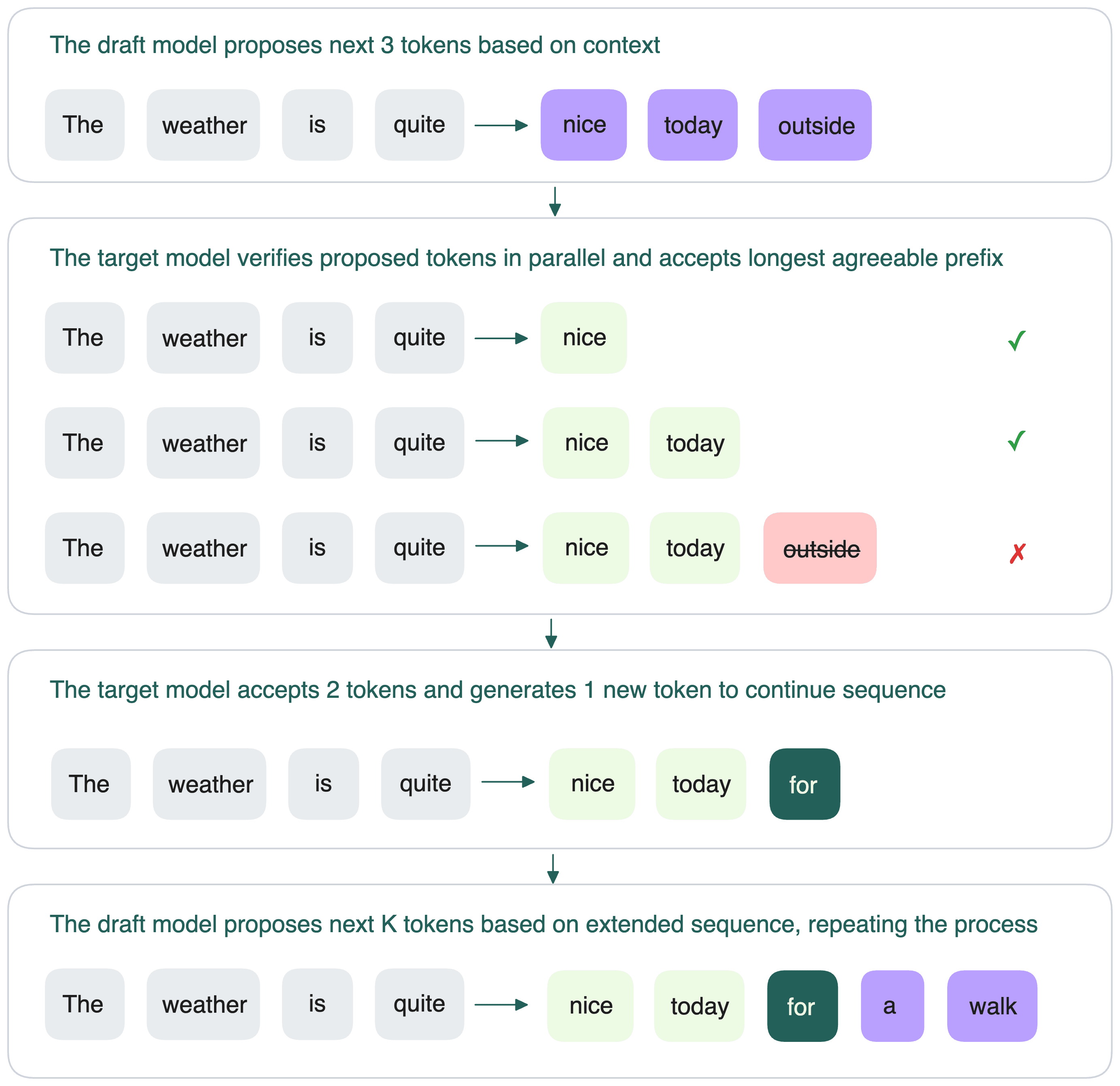
-
The draft model proposes the next
ktokens based on the current context. -
The target model then verifies these tokens in parallel.
- If it agrees with the draft model’s prediction at position
i, the token is accepted. - If not, the token is rejected, and all later tokens in the draft are discarded.
- If it agrees with the draft model’s prediction at position
-
The target model generates the next token after the last accepted one, and the cycle continues.
This technique parallelizes the expensive part (i.e. the forward pass) and replaces many slow sequential steps with a single verification, thus reducing ITL. It is helpful to interactive and latency-sensitive applications, such as:
- AI chatbots: Faster token generation means quicker replies, more natural conversations, and better user experience.
- Code completion tools: Developers expect instant suggestions. Even a slight delay per token can disrupt flow and reduce usability.
- AI agents and multi-turn reasoning: Agents often make multiple calls per task. Reducing ITL at each step speeds up decision-making end-to-end.
- Speech-to-text pipelines: These models decode audio in long sequences. Lower ITL directly improves perceived latency and output speed.
Why acceptance rate is important to speculative decoding performance#
Speculative decoding promises faster LLM inference, but only when it works well. And its effectiveness depends on a critical factor: how often the target model accepts the draft model’s predictions.
This is known as the acceptance rate (α). It is not a fixed number and can vary based on several factors like decoding strategy (e.g., nucleus vs. random sampling) and application domains.
-
High α means:
- More tokens accepted per speculative round
- Fewer target model forward passes
- Lower latency, higher throughput, better GPU utilization
-
Low α means:
- Many draft tokens are rejected
- Time and compute wasted on both generating and verifying unused tokens
- Falling back to sequential decoding more frequently, which defeats the point of speculative acceleration
Simulate the effect of acceptance rate#
To understand how acceptance rate impacts performance, we patched vLLM to simulate speculative decoding using theoretical acceptance rates. We bypassed the draft model and tested different speculative token counts (the number of tokens proposed by the draft model each step).
Here’s how we set it up:
- Target model: Llama-3.1-8B-Instruct
- Acceptance rates (α): 0.2, 0.4, 0.6, 0.8
- Speculative token counts (γ): 3, 5, 7, 9
- Baseline E2E latency (E2EL) without speculative decoding: 4065.42 ms
We evaluated the following metrics:
-
Output throughput (Output Tokens Per Second/TPS)
-
E2EL in milliseconds
-
Speedup relative to baseline
-
Acceptance length (τ): The average number of tokens accepted per round of decoding. According to the paper Fast Inference from Transformers via Speculative Decoding, theoretically, it is calculated with the formula:
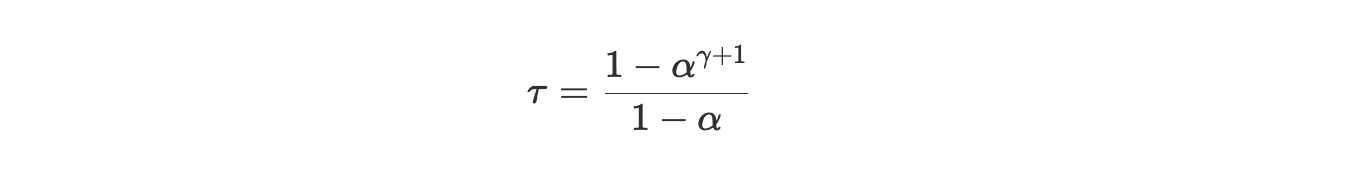
Here are the results:
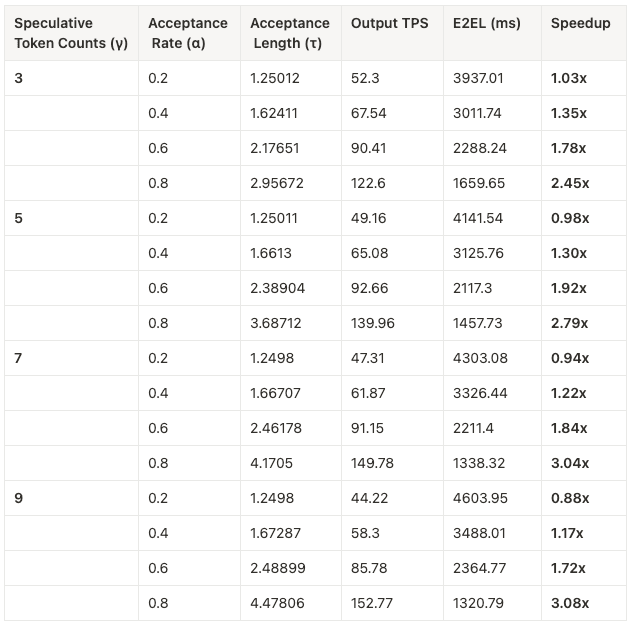
Key takeaways:
- The higher the acceptance rate (α), the greater the speedup.
- Speculative token counts (γ) should be increased only when the acceptance length is high. Otherwise, performance may be negatively affected.
- Latency drops and throughput rises almost linearly with α.
- At α ≥ 0.6 and γ ≥ 5, we observed 2–3× speedups over baseline decoding.
But how do you actually achieve a high acceptance rate in the real world?
Why the draft model makes or breaks speedup#
In the previous section, we showed that speculative decoding can offer up to 3× speedups, but only in theory. Those results were based on simulated acceptance rates, not actual draft model performance.
To understand how this works in practice, we ran real-world benchmarks using both vLLM and SGLang with and without their respective EAGLE 3 draft models.
Note: EAGLE improves on vanilla speculative decoding. It reuses the top-layer features of the target model (the features before the LM head). It trains the draft model to predict the next feature and then uses the target model’s LM head to obtain the draft token. By leveraging the rich information from the target model, EAGLE achieves significantly better acceleration compared to vanilla speculative sampling.
Here is our test setup:
- Target model: Llama-3.1-8B-Instruct
- Speculative token count (γ): 3
- Datasets: MT-Bench, HumanEval, CNN/DailyMail
- Baseline: Regular decoding without EAGLE 3
- Compared against: EAGLE 3-enabled draft models
Here are the measured results:
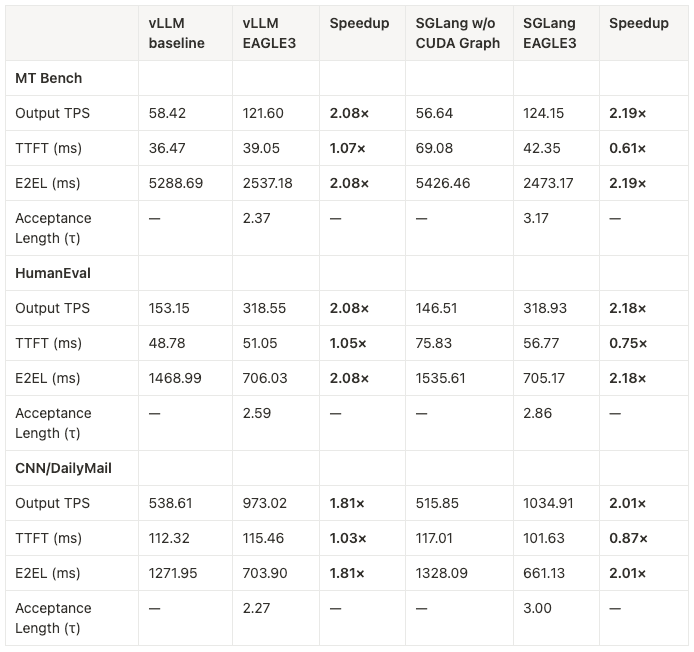
Despite achieving ~2× speedups, we found that real-world acceptance lengths (τ) were lower than ideal. Based on the test results in the previous section, the acceptance rates (α) were likely in the 0.6–0.8 range, not the near-perfect values used in theory.
We believe two major factors limit acceptance rates when using out-of-the-box EAGLE 3 draft models:
- Task domain mismatch: The datasets we used above are generic. If your dataset has specific characteristics, which is often the case in practice, the acceptance rate could be lower and the speedup might be worse.
- Context length mismatch: EAGLE 3 draft heads were not optimized for long contexts. If your use case involves long prompts, acceptance rates drop due to lack of alignment.
Based on these findings, our conclusion is:
- To consistently achieve high acceptance rates and up to 3x performance gains, you need to have the right draft model. For this purpose, you can train a custom draft model on your own data. This ensures it learns the patterns of your specific workload, leading to higher acceptance rates and faster inference.
- However, if your current model already yields a good acceptance rate for your use case, you don’t need extra training. Speculative decoding will still deliver decent speedups.
How to train your own draft model#
To validate our conclusion and test speculative decoding in practice, we trained a custom EAGLE 3 draft model using the official EAGLE repository.
- Dataset: A combined one of UltraChat-200k and ShareGPT
- Hardware: Training with 8 H200 GPUs
- Result: Achieved an acceptance rate (α) of 3.02 with 5 speculative tokens (γ = 5)
We successfully replicated EAGLE 3 and observed the hypothetical speedup in downstream inference benchmarks.
Here is how we did it.
Prepare the dataset#
The EAGLE repo provides a script to build a training dataset by mixing UltraChat-200k and ShareGPT. Run the script to convert both datasets to a shared ShareGPT-style format:
python eagle/train/eagle3/prepare.py
Note that:
- The default configuration is used for training on a single GPU. If you have 8 H200 GPUs, set
gradient_accumulation_steps = 8. This helps fully utilize available VRAM and accelerates the epoch. If you're using fewer GPUs, adjust this value accordingly. - For long-context support (e.g. 8k+ tokens), some customization is required in DeepSpeed to ensure proper context window handling.
- Optionally, set up wandb for tracking. If you don’t want to use it, comment out the wandb logic in the training code.
Evaluate the trained model#
Once configured, training can be launched. After 10 epochs, you’ll be ready to validate your draft model.
-
Copy your trained config into the state directory:
cp config.json output_dir/state_<epoch>/config.json -
Run vLLM with EAGLE 3:
VLLM_USE_V1=1 VLLM_LOGGING_LEVEL=DEBUG \ vllm serve meta-llama/Llama-3.1-8B-Instruct \ --max-model-len 8192 \ -tp 1 \ --speculative-config '{"method": "eagle3", "model": "path/to/state_dir", "num_speculative_tokens": 5, "draft_tensor_parallel_size": 1}' -
In a separate terminal, benchmark the setup and here is an example command:
vllm bench serve \ --save-result \ --sharegpt-output-len 1024 \ --dataset-name sharegpt \ --endpoint-type openai \ --ramp-up-strategy linear \ --ramp-up-start-rps 1 \ --ramp-up-end-rps 2 \ --label eagle3-2048-o1024-tp1 \ --model meta-llama/Llama-3.1-8B-Instruct \ --dataset-path ~/path/to/your/datasets \ --endpoint-type openai-chat \ --endpoint "/v1/chat/completions"
Conclusion#
Speculative decoding is a powerful technique to speed up LLM inference. It’s also a fast-moving research area. Other methods like LayerSkip and MTP are being actively explored and may offer further gains in the future.
Through both simulation and real-world benchmarks, we showed that:
- High acceptance rates are necessary to realizing meaningful gains, often 2–3× in throughput and latency.
- Generic, out-of-the-box draft models fall short when used in domain-specific or long-context workloads.
- Training your own draft model on your own data is helpful to aligning the draft model with your use case and achieving optimal performance.
If your LLM application is latency-sensitive, don’t just plug in speculative decoding as a drop-in solution. Benchmark it. Tune it. Train your draft model if necessary.
Still have questions?
- Join our community forum to learn from others and discuss speculative decoding
- Schedule a call with our inference experts
- Read our LLM Inference Handbook to learn more inference optimization techniques